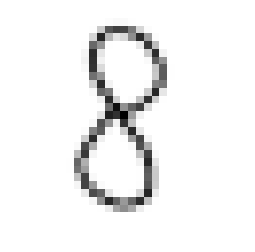PyTorch 中级篇(1):卷积神经网络(Convolutional Neural Network)
参考代码
yunjey的 pytorch tutorial系列
1 2 3 4 5 import torch import torch.nn as nnimport torchvisionimport torchvision.transforms as transforms
1 2 3 4 5 6 7 8 9 torch.cuda.set_device(1 ) device = torch.device('cuda' if torch.cuda.is_available() else 'cpu' ) num_epochs = 5 num_classes = 10 batch_size = 100 learning_rate = 0.001
cuda
MINIST数据集 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 train_dataset = torchvision.datasets.MNIST(root='../../../data/minist/' , train=True , transform=transforms.ToTensor(), download=True ) test_dataset = torchvision.datasets.MNIST(root='../../../data/minist' , train=False , transform=transforms.ToTensor()) train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True ) test_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=batch_size, shuffle=False )
自定义 卷积神经网络
参考阅读
卷积层的计算细节可以看这篇CNN中卷积层的计算细节
更详细的介绍,包括池化层的,可以看这篇卷积神经网络中的参数计算
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 class ConvNet (nn.Module): def __init__ (self, num_classes=10 ): super (ConvNet, self).__init__() self.layer1 = nn.Sequential( nn.Conv2d(1 , 16 , kernel_size=5 , stride=1 , padding=2 ), nn.BatchNorm2d(16 ), nn.ReLU(), nn.MaxPool2d(kernel_size=2 , stride=2 )) self.layer2 = nn.Sequential( nn.Conv2d(16 , 32 , kernel_size=5 , stride=1 , padding=2 ), nn.BatchNorm2d(32 ), nn.ReLU(), nn.MaxPool2d(kernel_size=2 , stride=2 )) self.fc = nn.Linear(7 *7 *32 , num_classes) def forward (self, x ): out = self.layer1(x) out = self.layer2(out) out = out.reshape(out.size(0 ), -1 ) out = self.fc(out) return out
1 2 3 4 5 6 model = ConvNet(num_classes).to(device) criterion = nn.CrossEntropyLoss() optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
训练模型 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 total_step = len (train_loader) for epoch in range (num_epochs): for i, (images, labels) in enumerate (train_loader): images = images.to(device) labels = labels.to(device) outputs = model(images) loss = criterion(outputs, labels) optimizer.zero_grad() loss.backward() optimizer.step() if (i+1 ) % 100 == 0 : print ('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}' .format (epoch+1 , num_epochs, i+1 , total_step, loss.item()))
Epoch [1/5], Step [100/600], Loss: 0.1291
Epoch [1/5], Step [200/600], Loss: 0.0968
Epoch [1/5], Step [300/600], Loss: 0.0393
Epoch [1/5], Step [400/600], Loss: 0.0646
Epoch [1/5], Step [500/600], Loss: 0.0740
Epoch [1/5], Step [600/600], Loss: 0.0696
Epoch [2/5], Step [100/600], Loss: 0.0408
Epoch [2/5], Step [200/600], Loss: 0.0071
Epoch [2/5], Step [300/600], Loss: 0.0650
Epoch [2/5], Step [400/600], Loss: 0.0279
Epoch [2/5], Step [500/600], Loss: 0.0141
Epoch [2/5], Step [600/600], Loss: 0.0352
Epoch [3/5], Step [100/600], Loss: 0.0073
Epoch [3/5], Step [200/600], Loss: 0.0716
Epoch [3/5], Step [300/600], Loss: 0.0376
Epoch [3/5], Step [400/600], Loss: 0.0233
Epoch [3/5], Step [500/600], Loss: 0.0459
Epoch [3/5], Step [600/600], Loss: 0.0058
Epoch [4/5], Step [100/600], Loss: 0.0181
Epoch [4/5], Step [200/600], Loss: 0.0847
Epoch [4/5], Step [300/600], Loss: 0.0789
Epoch [4/5], Step [400/600], Loss: 0.1064
Epoch [4/5], Step [500/600], Loss: 0.0511
Epoch [4/5], Step [600/600], Loss: 0.0647
Epoch [5/5], Step [100/600], Loss: 0.0101
Epoch [5/5], Step [200/600], Loss: 0.0263
Epoch [5/5], Step [300/600], Loss: 0.0121
Epoch [5/5], Step [400/600], Loss: 0.0828
Epoch [5/5], Step [500/600], Loss: 0.0515
Epoch [5/5], Step [600/600], Loss: 0.0401
测试并保存模型 ConvNet(
(layer1): Sequential(
(0): Conv2d(1, 16, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(layer2): Sequential(
(0): Conv2d(16, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(fc): Linear(in_features=1568, out_features=10, bias=True)
)
1 2 3 4 5 6 7 8 9 10 11 12 13 with torch.no_grad(): correct = 0 total = 0 for images, labels in test_loader: images = images.to(device) labels = labels.to(device) outputs = model(images) _, predicted = torch.max (outputs.data, 1 ) total += labels.size(0 ) correct += (predicted == labels).sum ().item() print ('Test Accuracy of the model on the 10000 test images: {} %' .format (100 * correct / total))
Test Accuracy of the model on the 10000 test images: 99.01 %
1 2 torch.save(model.state_dict(), 'model.ckpt' )
如何用自己的图片和模型进行测试(单张) 1 2 3 4 5 6 7 import matplotlib.pyplot as plt import matplotlib.image as mpimg import numpy as npfrom scipy import misc
1 2 3 def rgb2gray (rgb ): return np.dot(rgb[...,:3 ], [0.299 , 0.587 , 0.114 ])
1 2 3 4 5 6 7 8 9 10 srcPath = '8.png' src = mpimg.imread(srcPath) print (src.shape) plt.imshow(src) plt.axis('off' ) plt.show()
(225, 225, 3)
1 2 3 4 5 6 gray = rgb2gray(src) gray_new_sz = misc.imresize(gray, (28 ,28 ) ) print (gray_new_sz.shape)plt.imshow(gray_new_sz, cmap='Greys_r' ) plt.axis('off' )
(28, 28)
/home/ubuntu/anaconda3/lib/python3.6/site-packages/ipykernel_launcher.py:3: DeprecationWarning: `imresize` is deprecated!
`imresize` is deprecated in SciPy 1.0.0, and will be removed in 1.2.0.
Use ``skimage.transform.resize`` instead.
This is separate from the ipykernel package so we can avoid doing imports until
(-0.5, 27.5, 27.5, -0.5)
1 2 3 4 5 image = gray_new_sz.reshape(-1 ,1 ,28 ,28 ) image_tensor = torch.from_numpy(image).float ()
1 2 3 4 5 6 model.eval () output = model(image_tensor.to(device)) _, predicted = torch.max (output.data, 1 ) pre = predicted.cpu().numpy() print (pre)
[8]
友情Tip:查看Pytorch跑在哪块GPU上 遇到cuda runtime error: out of memory时,可以查看一下跑在哪块GPU上了。
然后用nvidia-smi看一下是不是GPU被占用了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 import torchimport sysprint ('__Python VERSION:' , sys.version)print ('__pyTorch VERSION:' , torch.__version__)print ('__CUDA VERSION' )from subprocess import call! nvcc --version print ('__CUDNN VERSION:' , torch.backends.cudnn.version())print ('__Number CUDA Devices:' , torch.cuda.device_count())print ('__Devices' )call(["nvidia-smi" , "--format=csv" , "--query-gpu=index,name,driver_version,memory.total,memory.used,memory.free" ]) print ('Active CUDA Device: GPU' , torch.cuda.current_device())print ('Available devices ' , torch.cuda.device_count())print ('Current cuda device ' , torch.cuda.current_device())
__Python VERSION: 3.6.5 |Anaconda, Inc.| (default, Apr 29 2018, 16:14:56)
[GCC 7.2.0]
__pyTorch VERSION: 0.4.1
__CUDA VERSION
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2017 NVIDIA Corporation
Built on Fri_Sep__1_21:08:03_CDT_2017
Cuda compilation tools, release 9.0, V9.0.176
__CUDNN VERSION: 7102
__Number CUDA Devices: 2
__Devices
Active CUDA Device: GPU 1
Available devices 2
Current cuda device 1