CS131,Homewrok5,Segmentation-Clustering
Homework 5
This notebook includes both coding and written questions. Please hand in this notebook file with all the outputs and your answers to the written questions.
This assignment covers K-Means and HAC methods for clustering.
这份作业包含的主题:用于聚类的K-means 和 HAC(层次凝聚聚类)方法,以及聚类算法的量化评估。
1 | # Setup |
The autoreload extension is already loaded. To reload it, use:
%reload_ext autoreload
Introduction
In this assignment, you will use clustering algorithms to segment images. You will then use these segmentations to identify foreground and background objects.
Your assignment will involve the following subtasks:
- Clustering algorithms: Implement K-Means clustering and Hierarchical Agglomerative Clustering.
- Pixel-level features: Implement a feature vector that combines color and position information and implement feature normalization.
- Quantitative Evaluation: Evaluate segmentation algorithms with a variety of parameter settings by comparing your computed segmentations against a dataset of ground-truth segmentations.
使用聚类算法实现图像分割,分割图像前景和背景。
作业分为这三步:
- 聚类算法的实现:实现K-Means聚类和层次凝聚聚类
- 像素级特征:实现结合颜色和位置信息的特征向量以及实现特征归一化。
- 量化评估:通过将计算出来的分割结果与GroundTruth进行比较,评估具有各种参数设置的分割算法。
量化评估这一块重要,我还没学过评估分割结果的方法
1 Clustering Algorithms (40 points)
1 | # Generate random data points for clustering |
1.1 K-Means Clustering (20 points)
As discussed in class, K-Means is one of the most popular clustering algorithms. We have provided skeleton code for K-Means clustering in the file segmentation.py. Your first task is to finish implementing kmeans in segmentation.py. This version uses nested for loops to assign points to the closest centroid and compute new mean of each cluster.
K-Means Wiki
目前题图允许使用循环实现点到最近中心的分配即可。
K-means的步骤:
- 随机初始化聚类中心
- 将点分配给最近的中心
- 计算每个聚类的新的中心
- 如果聚类的分配不再变动则停止
- 从第二步继续循环
1 | from segmentation import kmeans |
迭代次数 8
kmeans running time: 0.061108 seconds.
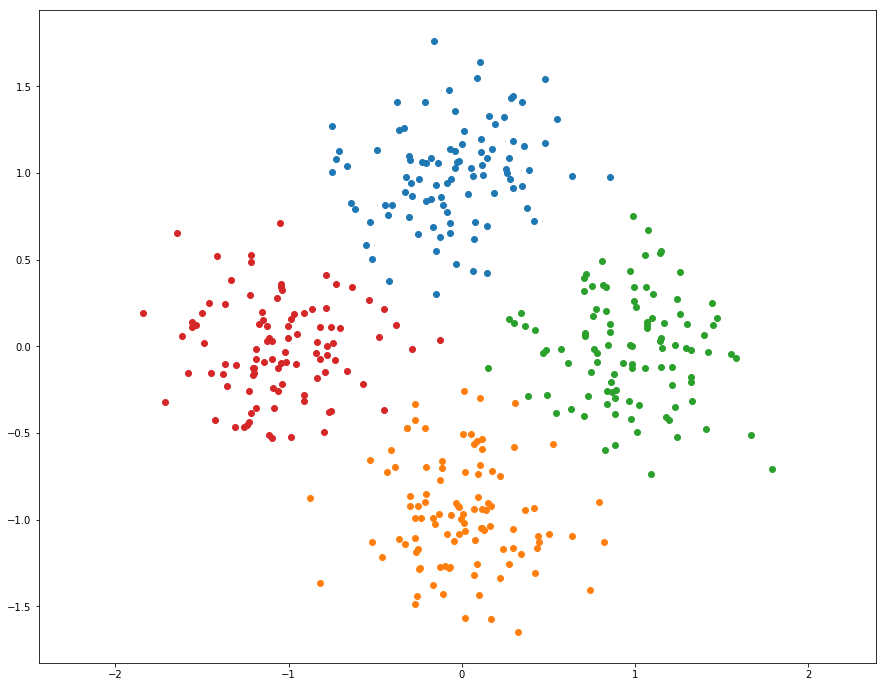
哈,简单的实现了K-Means算法,发现第三步判断终止条件很重要,添加了以后只迭代了几次就结束了,大大降低了运行时间。
We can use numpy functions and broadcasting to make kmeans faster. Implement kmeans_fast in segmentation.py. This should run at least 10 times faster than the previous implementation.
又是加快运算速度的老要求。
想想思路:
- 题目的提示是使用numpy函数和broadcasting机制
- np.repeat and np.argmin 有帮助
- 还有一种思路就是向量化了,不做迭代而是放在矩阵里去计算。
1 | from segmentation import kmeans_fast |
kmeans running time: 0.003889 seconds.
15.714531 times faster!
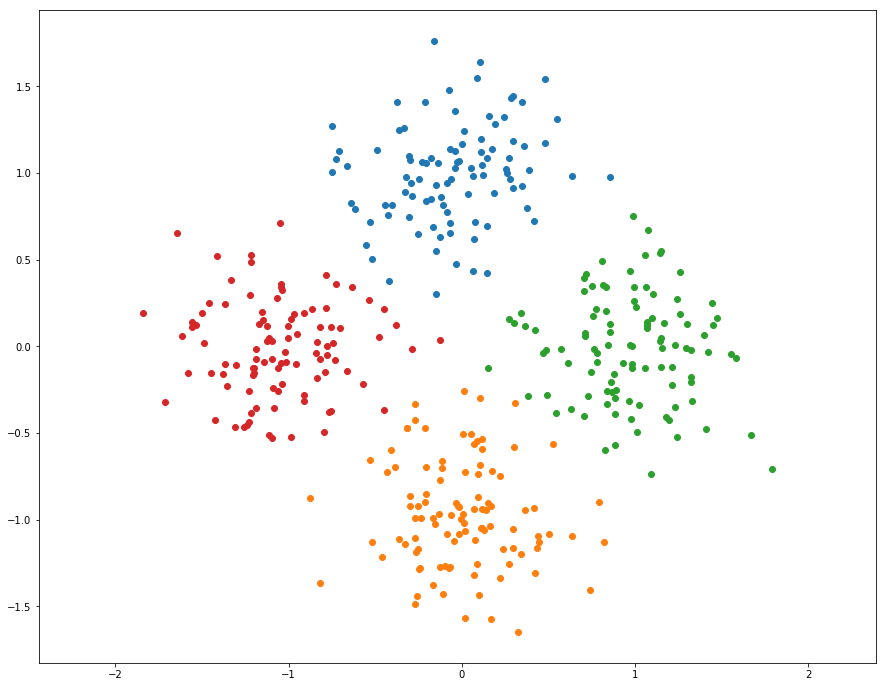
快了十六倍 ,666,向量化是个好东西!!!
1.2 Hierarchical Agglomerative Clustering (20 points)
Another simple clustering algorithm is Hieararchical Agglomerative Clustering, which is somtimes abbreviated as HAC. In this algorithm, each point is initially assigned to its own cluster. Then cluster pairs are merged until we are left with the desired number of predetermined clusters (see Algorithm 1).
Implement hiererachical_clustering in segmentation.py.

按照上图的算法定义是:
- 初始化每个点为一个簇
- 迭代直到只剩下K个簇:
- 计算所有簇与簇之间(簇对)的距离
- 合并最近的两个簇
这个算法的关键,主要是如何定义簇与簇之间的距离。定义有下面三种:
- 1)单链(Single-link):不同两个聚类中离得最近的两个点之间的距离,即MIN;
- 2)全链(Complete-link):不同两个聚类中离得最远的两个点之间的距离,即MAX;
- 3)平均链(Average-link):不同两个聚类中所有点对距离的平均值,即AVERAGE;
题目代码中提示的做法是,利用簇中心的欧几里得距离来定义簇与簇之间的距离。
hierarchical_clustering函数将按照这个思路实现。
** 博客推荐 **
Numpy中的距离度量函数
1 | from segmentation import hierarchical_clustering |
hierarchical_clustering running time: 0.191211 seconds.
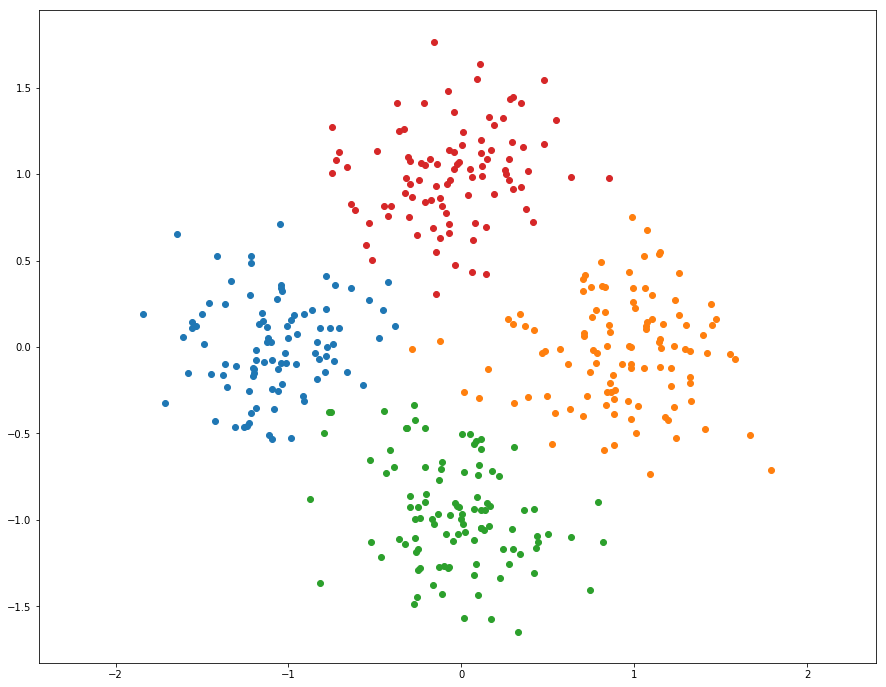
运行时间比预期的块,总结一下就是这类算法的提速方式:
- 第一个是善用向量化,用矩阵来计算问题
- 第二个就是善用numpy提供的函数,解决一些需要搜索遍历的问题
2 Pixel-Level Features (30 points)
Before we can use a clustering algorithm to segment an image, we must compute some feature vectore for each pixel. The feature vector for each pixel should encode the qualities that we care about in a good segmentation. More concretely, for a pair of pixels $p_i$ and $p_j$ with corresponding feature vectors $f_i$ and $f_j$, the distance between $f_i$ and $f_j$ should be small if we believe that $p_i$ and $p_j$ should be placed in the same segment and large otherwise.
上一步的聚类算法实现其实是流程的第二步,第一步其实是特征的提取,有了特征才能进行像素(或者说样本)的聚类。只不过第一步中,拿了点的位置作为特征来进行聚类了。
1 | # Load and display image |

2.1 Color Features (15 points)
One of the simplest possible feature vectors for a pixel is simply the vector of colors for that pixel. Implement color_features in segmentation.py. Output should look like the following:
在color_features实现简单的颜色特征的聚类。
1 | from segmentation import color_features |

In the cell below, we visualize each segment as the mean color of pixels in the segment.
将聚类结果用颜色进行显示(颜色是指源图各个分割区域内的颜色均值)
1 | from utils import visualize_mean_color_image |

2.2 Color and Position Features (15 points)
Another simple feature vector for a pixel is to concatenate its color and position within the image. In other words, for a pixel of color $(r, g, b)$ located at position $(x, y)$ in the image, its feature vector would be $(r, g, b, x, y)$. However, the color and position features may have drastically different ranges; for example each color channel of an image may be in the range $[0, 1)$, while the position of each pixel may have a much wider range. Uneven scaling between different features in the feature vector may cause clustering algorithms to behave poorly.
One way to correct for uneven scaling between different features is to apply some sort of normalization to the feature vector. One of the simplest types of normalization is to force each feature to have zero mean and unit variance.
Implement color_position_features in segmentation.py.
Output segmentation should look like the following:
结合颜色特征和位置特征的聚类
其实就是生成特征为 $(r,g,b,x,y)$的序列,但需要考虑的问题是尺度的不同,解决的方案也很简单,就是进行归一化,对每一个维度进行归一化。公式如下:
$$
feature_{new} = \frac{(feature - Mean(feature))}{Std (feature)}
$$
知识点补充
1 | from segmentation import color_position_features |

1 | visualize_mean_color_image(img, segments) |

Extra Credit: Implement Your Own Feature
For this programming assignment we have asked you to implement a very simple feature transform for each pixel. While it is not required, you should feel free to experiment with other feature transforms. Could your final segmentations be improved by adding gradients, edges, SIFT descriptors, or other information to your feature vectors? Could a different type of normalization give better results?
Implement your feature extractor my_features in segmentation.py
Depending on the creativity of your approach and the quality of your writeup, implementing extra feature vectors can be worth extra credit (up to 5% of total points).
Describe your approach: (YOUR APPROACH)
实现自己定义的特征
可以实现一些简单的特征,比如添加梯度、边缘、SIFT描述子或者其他信息。
我添加了一个梯度强度信息,结合颜色特征,位置特征。
1 | from segmentation import my_features |

效果看上去还可以,就是后面的量化评估并没有好成绩。
3 Quantitative Evaluation (30 points)
Looking at images is a good way to get an idea for how well an algorithm is working, but the best way to evaluate an algorithm is to have some quantitative measure of its performance.
For this project we have supplied a small dataset of cat images and ground truth segmentations of these images into foreground (cats) and background (everything else). We will quantitatively evaluate different segmentation methods (features and clustering methods) on this dataset.
We can cast the segmentation task into a binary classification problem, where we need to classify each pixel in an image into either foreground (positive) or background (negative). Given the ground-truth labels, the accuracy of a segmentation is $(TP+TN)/(P+N)$.
Implement compute_accuracy in segmentation.py.
实现准确率计算就是正确个数与总个数之比。
1 | from segmentation import compute_accuracy |
Accuracy: 0.97

You can use the script below to evaluate a segmentation method’s ability to separate foreground from background on the entire provided dataset. Use this script as a starting point to evaluate a variety of segmentation parameters.
下面这段程序是已经完成的,主要逻辑就是
- 加载数据集,包括原图和分割结果真值
- 调用之前实现的聚类分割算法进行分割
- 将真值和分割结果进行比对,计算准确率
可以在下面进行调参,更改参数,查看效果。
1 | from utils import load_dataset, compute_segmentation |
/home/ubuntu/anaconda3/lib/python3.6/site-packages/skimage/transform/_warps.py:84: UserWarning: The default mode, 'constant', will be changed to 'reflect' in skimage 0.15.
warn("The default mode, 'constant', will be changed to 'reflect' in "
Accuracy for image 0: 0.8330
Accuracy for image 1: 0.9221
Accuracy for image 2: 0.9859
Accuracy for image 3: 0.8517
Accuracy for image 4: 0.6973
Accuracy for image 5: 0.7073
Accuracy for image 6: 0.6290
Accuracy for image 7: 0.5707
Accuracy for image 8: 0.9028
Accuracy for image 9: 0.9225
Accuracy for image 10: 0.8701
Accuracy for image 11: 0.6352
Accuracy for image 12: 0.8259
Accuracy for image 13: 0.6570
Accuracy for image 14: 0.7508
Accuracy for image 15: 0.6221
Mean accuracy: 0.7740
1 | # Visualize segmentation results |

Include a detailed evaluation of the effect of varying segmentation parameters (feature transform, clustering method, number of clusters, resize) on the mean accuracy of foreground-background segmentations on the provided dataset. You should test a minimum of 10 combinations of parameters. To present your results, add rows to the table below (you may delete the first row).
| Feature Transform | Clustering Method | Number of segments | Scale | Mean Accuracy |
|---|---|---|---|---|
| Color | K-Means | 3 | 0.5 | 0.7979 |
| Color | K-Means | 4 | 0.5 | 0.7664 |
| Color | K-Means | 2 | 0.5 | 0.7609 |
| Color | K-Means | 3 | 0.4 | 0.7904 |
| Color | K-Means | 3 | 0.6 | 0.7935 |
| Color | K-Means | 3 | 0.8 | 0.7963 |
| Color | K-Means | 3 | 1 | 0.7974 |
| Color-Postion | K-Means | 3 | 1 | 0.7767 |
| Color-Postion | K-Means | 3 | 0.5 | 0.7883 |
| ... | ... | ... | ... | ... |
Observe your results carefully and try to answer the following question:
- Based on your quantitative experiments, how do each of the segmentation parameters affect the quality of the final foreground-background segmentation?
- Are some images simply more difficult to segment correctly than others? If so, what are the qualities of these images that cause the segmentation algorithms to perform poorly?
- Also feel free to point out or discuss any other interesting observations that you made.
Write your analysis in the cell below.
Your answer here:
基于对结果的观察:
- 基于颜色-位置特征的聚类效果比基于颜色特征的聚类效果差
- 聚类数目3个就是最好的了,增大减小都影响效果
- 尺度是越接近原图,也就是越接近1,准确度越高
的确存在一些图更难识别。这些图的一些特性包括
- 背景较为复杂
- 前景颜色、亮度都与背景较为接近
我发现在基于颜色-位置特征的聚类中,尺度并不是越大越好,可能是我做的实验次数不够多。