Sacred 深度学习实验管理工具
深度学习实验管理
Every experiment is sacred
Every experiment is great
If an experiment is wasted
God gets quite irate
最近研究深度学习在目标检测领域的应用,在测试调整检测框架以及炼丹调参的情况时,常有的困惑就是如何保留每一次实验的实验数据,因为每次实验小意思就三四个小时,中等意思就两三天,每次跑下来的数据都应当保存下来留作后续分析,而不是看它效果不行,就直接删除了。注意这里的实验数据并不仅仅包括代码和训练结果,还应当包括
- 实验的参数配置
- 实验运行的环境
- GPU信息
- python 依赖
- 主机信息
- 实验过程的各类指标变化信息
- 实验的输出
日常使用中,要改的东西主要集中在代码[模型结构和训练流程]+参数[各类超参],对于代码改进,勤用Git进行版本管理;对于参数设置,统一管理在配置文件中;上面其他的实验数据除了养成良好的习惯进行手动保存备份之外,似乎没有更方便的方式了。
最近找到一个名为Sacred的工具,用于记录实验的配置、组织、日志和复现。我今天测试了一下,Sacred主要的工作在于将每次实验的输入-过程-输出保存到数据库中,并利用Web将历史实验数据进行了可视化,方便我们查看历史实验,并进行参数配置和实验结果的比较。
下面记录一下Sacred的安装过程和使用案例。
安装
Github 主页: Sacred
Sacred 文档:Welcome to Sacred’s documentation!
Sacred的使用有两部分:
- Sacred + MongoDB:实验记录和保存
- Ominiboard:可视化管理
备注:
- Sacred的数据保存后端有多种形式:Mongo Observer、File Storage Observer、TinyDB Observer、Telegram Observer等,我选择第一种Mongo Observer。其他的方式可以查看文档。
- Sacred的可视化前端也支持多种形式:Omniboard、Sacredboard、SacredBrowser等,我选择第一种Omniboard。其他的方式可以在Github主页上找到入口。
Sacred
1 | # 主角 |
MongoDB
MongoDB是一个数据库管理系统,这里用作Sacred的存储后端。
在ubuntu上的MongoDB安装可以参考Install MongoDB Community Edition on Ubuntu,其他系统也可以在该网站上找到对应的安装方式。
这里重复一下安装的过程:
1 | # 1. Import the public key used by the package management system. |
友情提醒:按这种方式,下载比较缓慢。
我是用梯子安装的,网络条件不好的话,可以参考清华大学开源软件镜像站的MongoDB 镜像使用帮助。
Tips:MongoDB的日常使用:
1 | # 启动 |
创建一个名为sacred的数据库,用作sacred工具的后端存储:
1 | # 进入MongoDB |
Omniboard
Omniboard效果图:
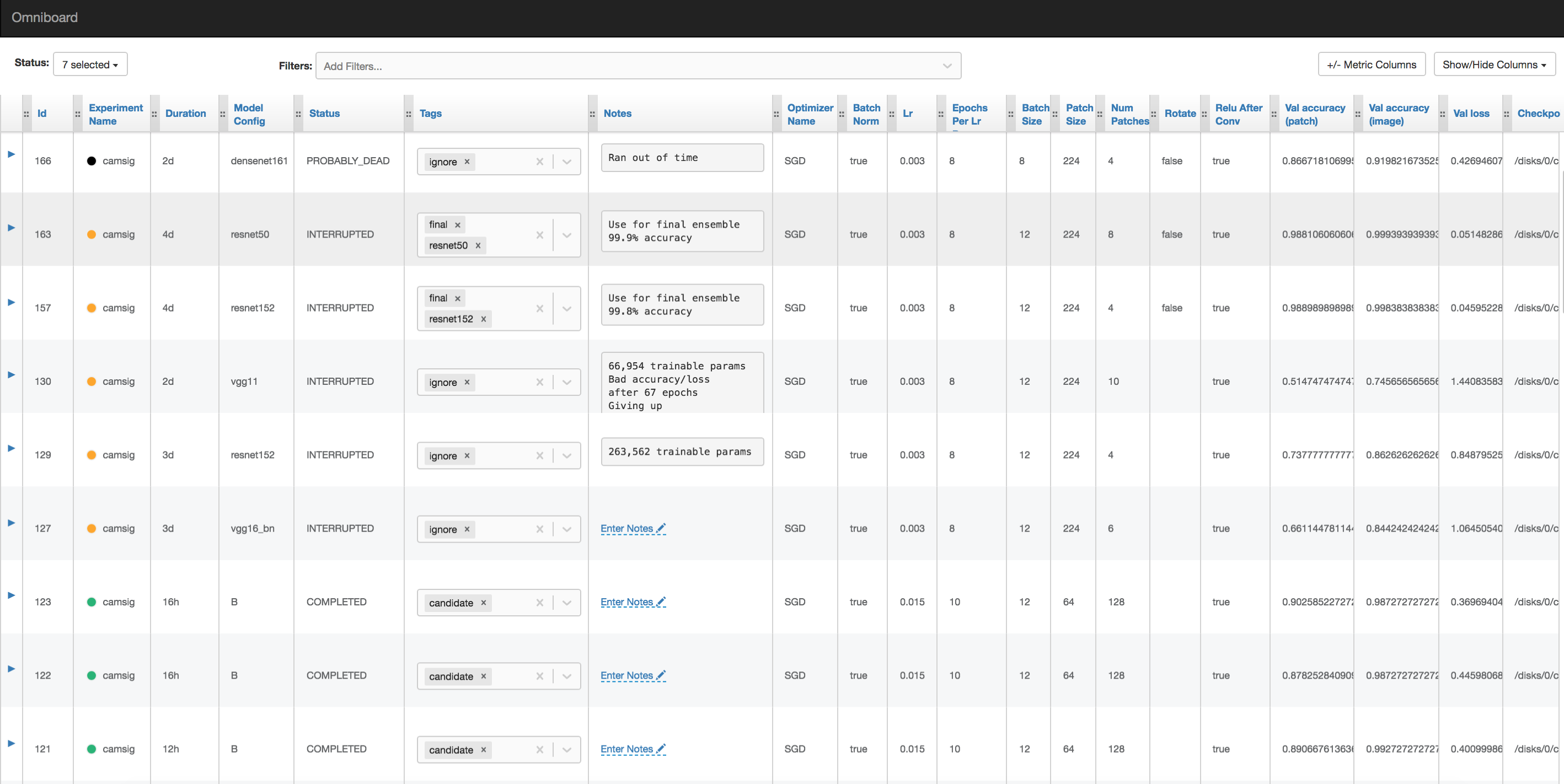
Github Repo: Omniboard
Guide上有两种方式:NPM 和 Docker,我用第一种npm的方式。
第一步,在Ubuntu机器上安装版本≥v8的Node.js,系统默认apt 安装的版本不够,需要手动安装,以下是安装步骤:
1 | # 0. 从官网下载编译好的node.js |
第二步,npm 安装omniboard
1 | npm install -g omniboard |
第三步,开启omniboard服务。平时也是用该命令开启omniboard可视化前端
1 | # 开启用法 |
第四步,打开 http://localhost:9000 来查看前端,并进行管理。
使用案例
使用yunjey的一个pytorch教程作为演示,代码是演示用pytorch实现基于CNN的MINIST手写数字识别。
根据Sacred文档稍作修改,就可以演示如何进行实验的记录。
更多用法请去看Sacred 文档:Welcome to Sacred’s documentation!。内容超丰富,功能超级多。
代码:
1 | from sacred import Experiment |
执行完该程序后,可以打开omniboard前端 http://localhost:9000 ,效果如图:
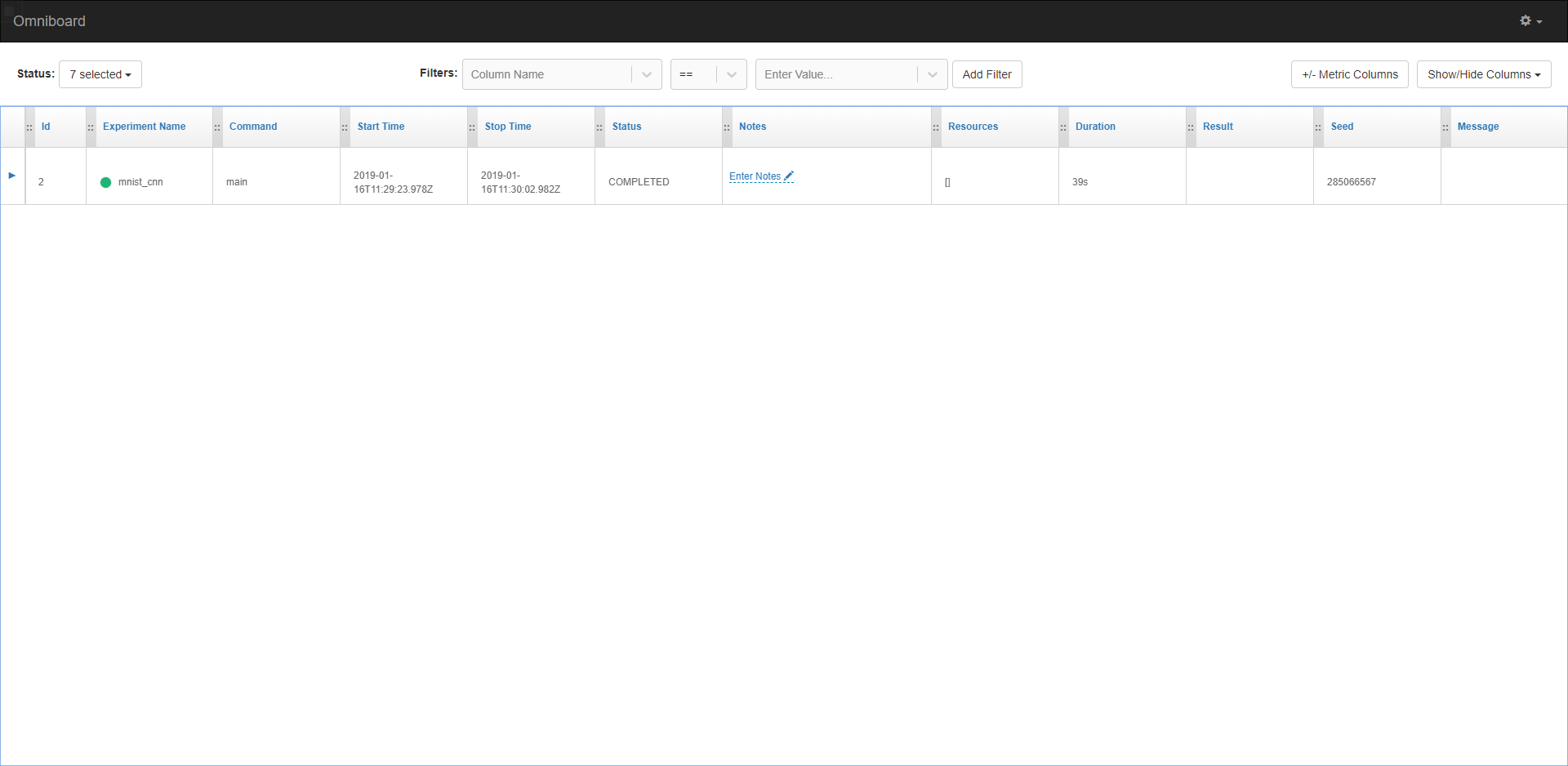
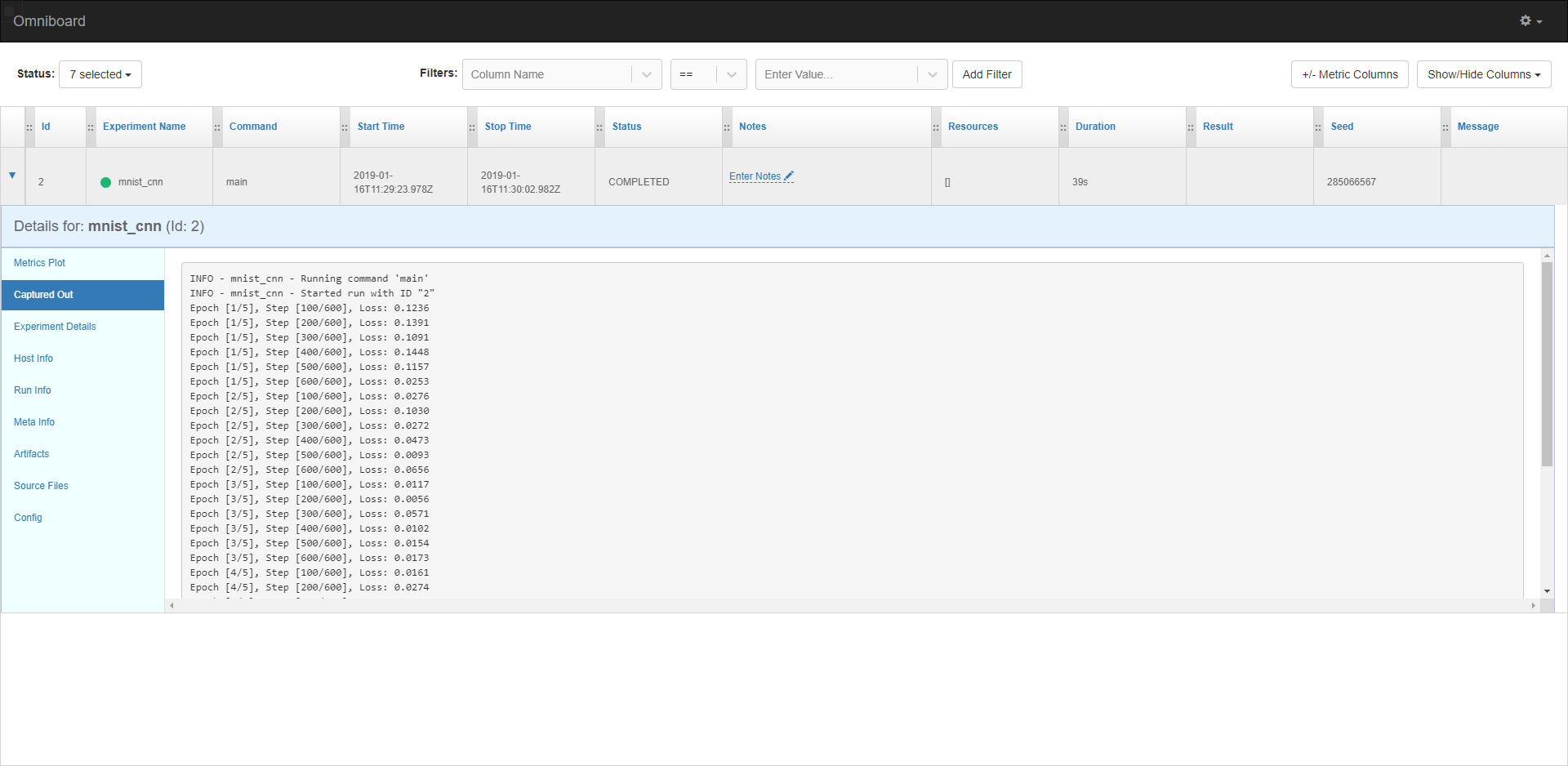
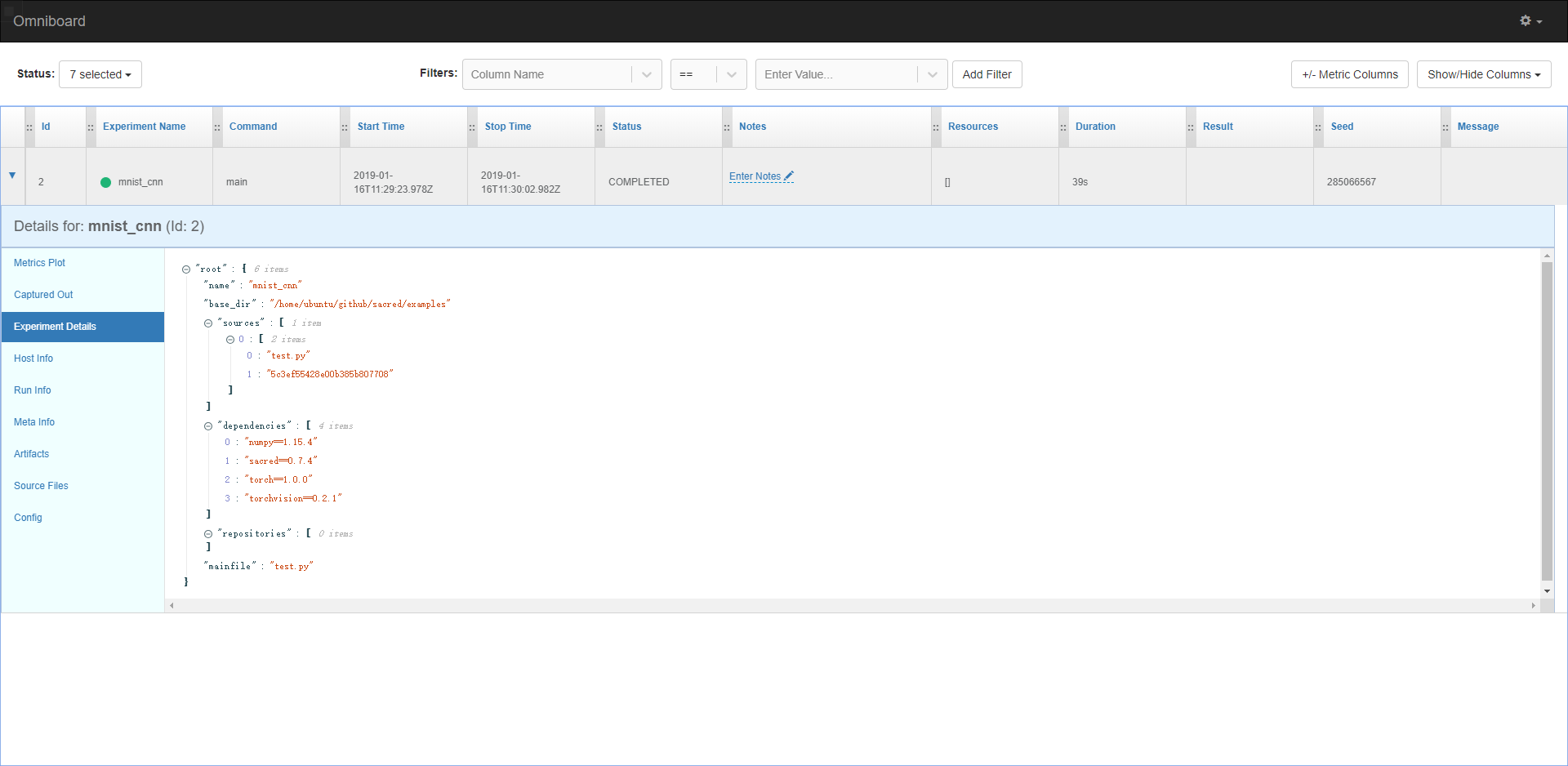

有啥问题欢迎讨论啊。