# 函数:构建词汇 defbuild_vocab(json, threshold): """Build a simple vocabulary wrapper.""" coco = COCO(json) counter = Counter() ids = coco.anns.keys() for i, idinenumerate(ids): caption = str(coco.anns[id]['caption']) tokens = nltk.tokenize.word_tokenize(caption.lower()) counter.update(tokens)
if (i+1) % 1000 == 0: print("[{}/{}] Tokenized the captions.".format(i+1, len(ids)))
# If the word frequency is less than 'threshold', then the word is discarded. words = [word for word, cnt in counter.items() if cnt >= threshold]
# Create a vocab wrapper and add some special tokens. vocab = Vocabulary() vocab.add_word('<pad>') vocab.add_word('<start>') vocab.add_word('<end>') vocab.add_word('<unk>')
# Add the words to the vocabulary. for i, word inenumerate(words): vocab.add_word(word) return vocab
1 2 3 4 5 6 7 8
# 定义执行函数 defbuild_vocab_main(args): vocab = build_vocab(json=args.caption_path, threshold=args.threshold) vocab_path = args.vocab_path withopen(vocab_path, 'wb') as f: pickle.dump(vocab, f) print("Total vocabulary size: {}".format(len(vocab))) print("Saved the vocabulary wrapper to '{}'".format(vocab_path))
loading annotations into memory...
Done (t=0.89s)
creating index...
index created!
[1000/414113] Tokenized the captions.
[2000/414113] Tokenized the captions.
[3000/414113] Tokenized the captions.
[4000/414113] Tokenized the captions.
[5000/414113] Tokenized the captions.
..........................
[409000/414113] Tokenized the captions.
[410000/414113] Tokenized the captions.
[411000/414113] Tokenized the captions.
[412000/414113] Tokenized the captions.
[413000/414113] Tokenized the captions.
[414000/414113] Tokenized the captions.
Total vocabulary size: 9957
Saved the vocabulary wrapper to '/home/ubuntu/Datasets/coco/vocab.pkl'
# 包 import argparse import os from PIL import Image
1 2 3 4
# 定义函数 Resize图像 defresize_image(image, size): """Resize an image to the given size.""" return image.resize(size, Image.ANTIALIAS)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
# 定义函数 Resize 图像序列 defresize_images(image_dir, output_dir, size): """Resize the images in 'image_dir' and save into 'output_dir'.""" ifnot os.path.exists(output_dir): os.makedirs(output_dir)
images = os.listdir(image_dir) num_images = len(images) for i, image inenumerate(images): withopen(os.path.join(image_dir, image), 'r+b') as f: with Image.open(f) as img: img = resize_image(img, size) img.save(os.path.join(output_dir, image), img.format) if (i+1) % 100 == 0: print ("[{}/{}] Resized the images and saved into '{}'." .format(i+1, num_images, output_dir))
# 通过argparse传参数 # 注意指定数据集相关文件的路径 parser = argparse.ArgumentParser() parser.add_argument('--image_dir', type=str, default='/home/ubuntu/Datasets/coco/train2014/', help='directory for train images') parser.add_argument('--output_dir', type=str, default='/home/ubuntu/Datasets/coco/resized2014/', help='directory for saving resized images') parser.add_argument('--image_size', type=int, default=256, help='size for image after processing') config = parser.parse_args(args=[]) resize_main(config)
[100/82783] Resized the images and saved into '/home/ubuntu/Datasets/coco/resized2014/'.
[200/82783] Resized the images and saved into '/home/ubuntu/Datasets/coco/resized2014/'.
[300/82783] Resized the images and saved into '/home/ubuntu/Datasets/coco/resized2014/'.
[400/82783] Resized the images and saved into '/home/ubuntu/Datasets/coco/resized2014/'.
[500/82783] Resized the images and saved into '/home/ubuntu/Datasets/coco/resized2014/'.
[600/82783] Resized the images and saved into '/home/ubuntu/Datasets/coco/resized2014/'.
[700/82783] Resized the images and saved into '/home/ubuntu/Datasets/coco/resized2014/'.
[800/82783] Resized the images and saved into '/home/ubuntu/Datasets/coco/resized2014/'.
............................
[82400/82783] Resized the images and saved into '/home/ubuntu/Datasets/coco/resized2014/'.
[82500/82783] Resized the images and saved into '/home/ubuntu/Datasets/coco/resized2014/'.
[82600/82783] Resized the images and saved into '/home/ubuntu/Datasets/coco/resized2014/'.
[82700/82783] Resized the images and saved into '/home/ubuntu/Datasets/coco/resized2014/'.
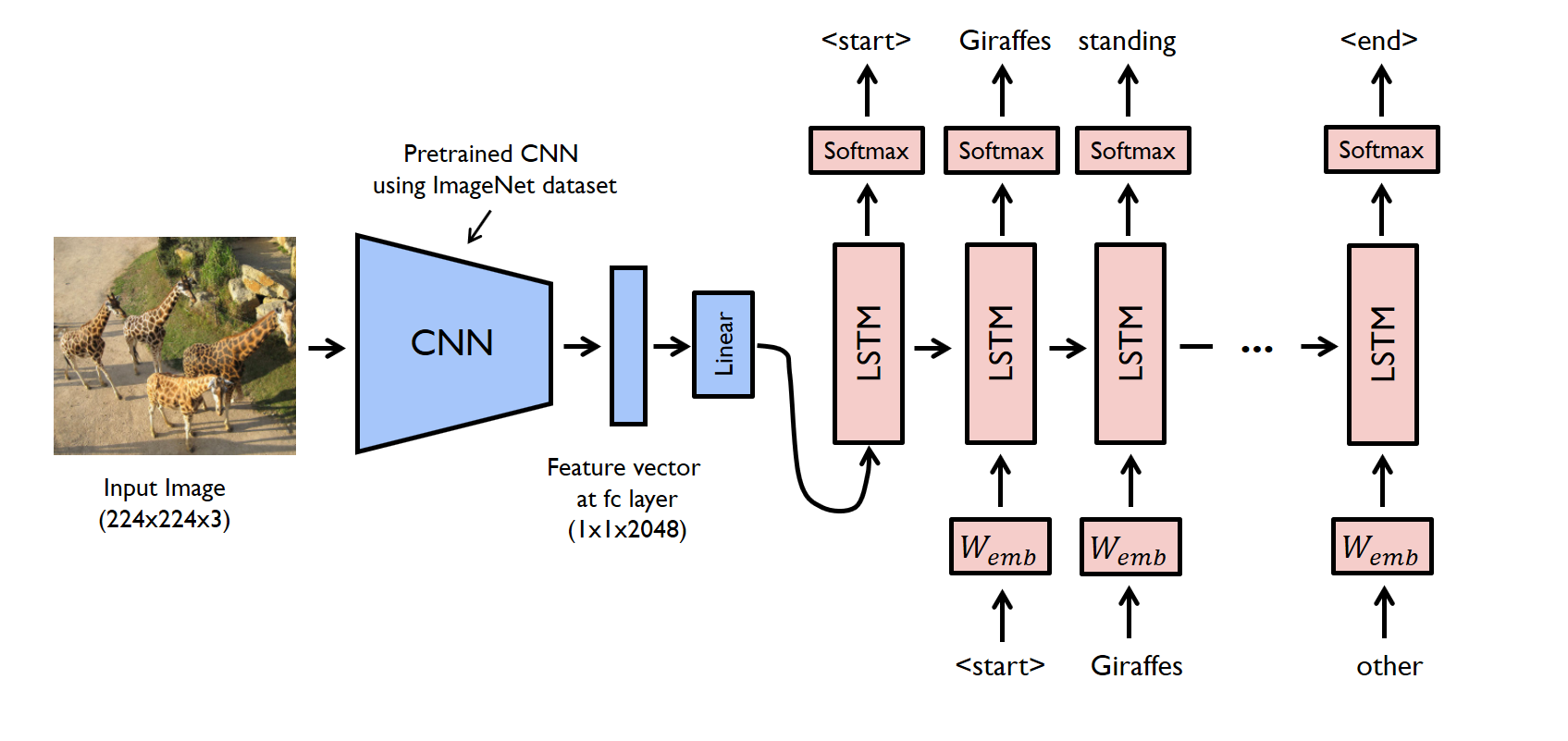
# 包 import torch import torchvision.transforms as transforms import torch.utils.data as data import os import pickle import numpy as np import nltk from PIL import Image # from build_vocab import Vocabulary # jupyter上已经定义好了函数 from pycocotools.coco import COCO
# 函数:从元组(image,caption)序列创建 mini-batch # 之所以需要自己创建是因为默认不支持merging caption (including padding) i defcollate_fn(data): """Creates mini-batch tensors from the list of tuples (image, caption). We should build custom collate_fn rather than using default collate_fn, because merging caption (including padding) is not supported in default. Args: data: list of tuple (image, caption). - image: torch tensor of shape (3, 256, 256). - caption: torch tensor of shape (?); variable length. Returns: images: torch tensor of shape (batch_size, 3, 256, 256). targets: torch tensor of shape (batch_size, padded_length). lengths: list; valid length for each padded caption. """ # Sort a data list by caption length (descending order). data.sort(key=lambda x: len(x[1]), reverse=True) images, captions = zip(*data)
# Merge images (from tuple of 3D tensor to 4D tensor). images = torch.stack(images, 0)
# Merge captions (from tuple of 1D tensor to 2D tensor). lengths = [len(cap) for cap in captions] targets = torch.zeros(len(captions), max(lengths)).long() for i, cap inenumerate(captions): end = lengths[i] targets[i, :end] = cap[:end] return images, targets, lengths
# 包 import argparse import torch import torch.nn as nn import numpy as np import os import pickle # from data_loader import get_loader # from build_vocab import Vocabulary # from model import EncoderCNN, DecoderRNN from torch.nn.utils.rnn import pack_padded_sequence from torchvision import transforms
# 包 import torch import matplotlib.pyplot as plt import numpy as np import argparse import pickle import os from torchvision import transforms # from build_vocab import Vocabulary # from model import EncoderCNN, DecoderRNN from PIL import Image
# 设置参数进行测试 parser = argparse.ArgumentParser() parser.add_argument('--image', type=str, default='png/football2.jpg', help='input image for generating caption') parser.add_argument('--encoder_path', type=str, default='models/encoder-5-3000.ckpt', help='path for trained encoder') parser.add_argument('--decoder_path', type=str, default='models/decoder-5-3000.ckpt', help='path for trained decoder') parser.add_argument('--vocab_path', type=str, default='/home/ubuntu/Datasets/coco/vocab.pkl', help='path for vocabulary wrapper')
# Model parameters (should be same as paramters in train.py) parser.add_argument('--embed_size', type=int , default=256, help='dimension of word embedding vectors') parser.add_argument('--hidden_size', type=int , default=512, help='dimension of lstm hidden states') parser.add_argument('--num_layers', type=int , default=1, help='number of layers in lstm') config = parser.parse_args(args=[]) test(config)
<start> a soccer player kicking a ball on a field . <end>