YOLO v1 论文阅读笔记
YOLO-v1 论文笔记
《You Only Look Once: Unified, Real-Time Object Detection》论文笔记。
资源
链接:You Only Look Once: Unified, Real-Time Object Detection
PDF:PDF
YOLO特色
- 将检测流程设计成一个回归问题,使用单个网络同时预测物体的BBox和分类概率。
- 非常快,YOLO版本能达到45帧/秒,Fast YOLO版本能达到155帧每秒,同时准确率远超其他实时目标检测器
- 实际上,实验部分更多的是强调YOLO的快,以及如何在保持实时性能的情况下,将精度向Fast R-CNN看齐。
- 定位能力稍差,但背景(background)检测能力较强,针对Fast R-CNN。
- 泛化能力较强,能学习非常基础的表征。从自然图像转到其他领域图像的检测时,泛化能力比DPM、R-CNN出色。
YOLO缺点
- 对BBox预测的空间限制:
每个网格只能预测两个Box和一个类别,导致检测到的扎堆的物体数目是有限的。
所以YOLO在群体小目标识别上非常困难,比如鸟群。 - YOLO较难泛化到新的/不常见的宽高比的对象上。
同时,YOLO进行多个下采样后在较粗糙的特征层上进行预测的,同样导致泛化性能差。 - 损失函数设置不合理,大BBox和小BBox的权重相同:在大BBox上有小的误差是良性的,在小BBox上小的误差会对IOU有更大的影响。
- YOLO的错误主要来自定位,而非分类。
YOLO检测框架介绍(Unified Detection)
基本思路
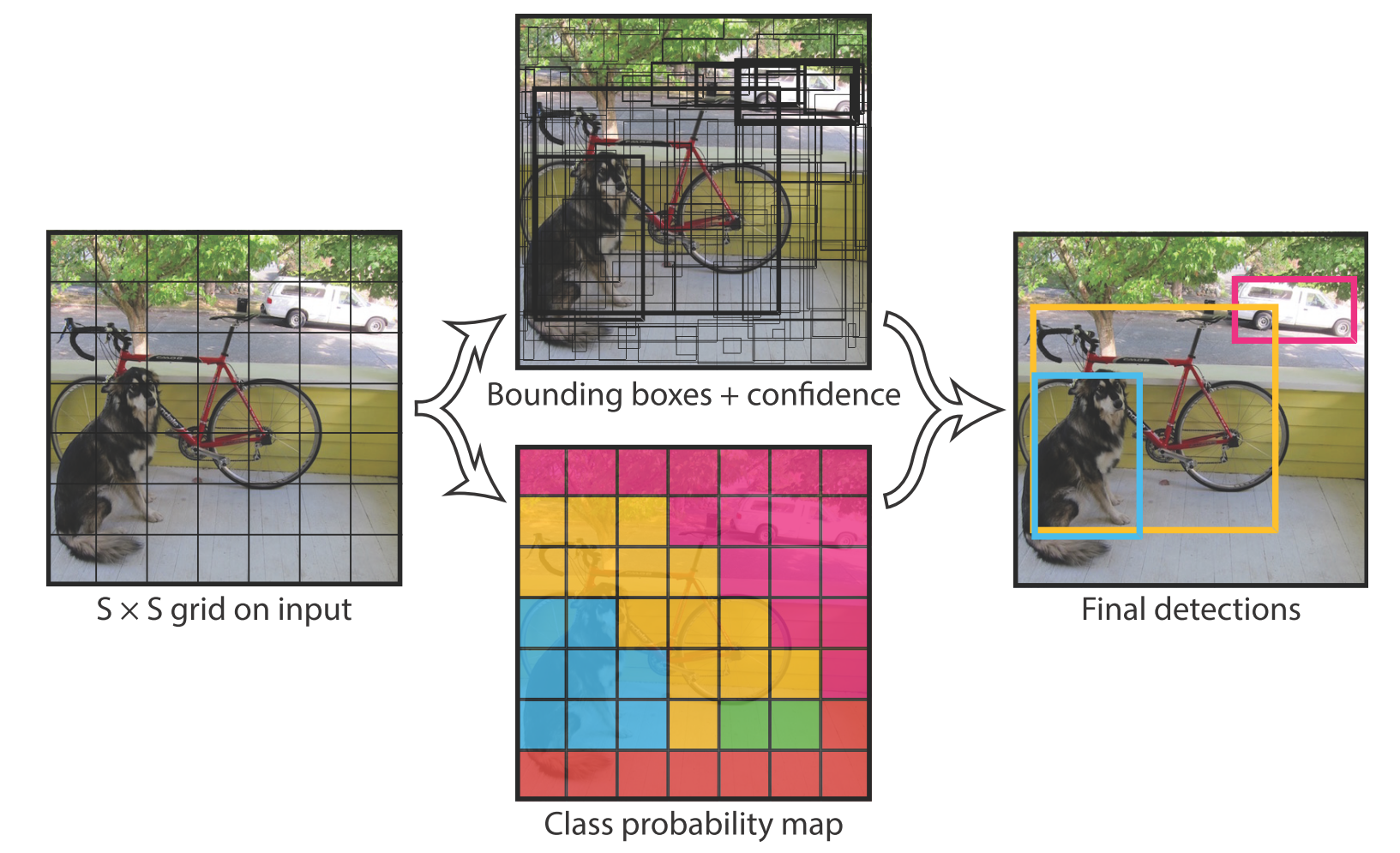
端到端训练,同时预测物体BBox和物体分类。
网格划分:将输入图像分成$S*S$个网格(grid cell)。如果数据集图像的目标中心落在其中一个网格内,则该网格对该目标负责(负责即是参与该目标的预测损失计算)。
网格输出:
每个网格最终预测输$B$个BBox,每个BBox对应5个输出:$x,y,w,h$ 和置信度,置信度的计算在文中第二章有讲公式,置信度等于该BBox内预测物体分类的概率乘上该BBox与Ground Truth的IoU,同时表达了BBox内物体分类预测的准确率以及BBox位置预测的准确率。
每个网格同时也预测C个条件概率(C为样本总的分类数目),条件概率是指当网格内存在物体时的分类概率。注意:无论网格内预测多少个BBox,一个网格只预测一组这种条件概率。
注意,
参数设定:论文在PASCAL VOC进行测试时,使用$S=7, B=2,C=20$,所以网络最终输出的tensor数目为 $S·S·(B·5+C) = (7·7·(2·5+20))=7·7·30 $
网络设计
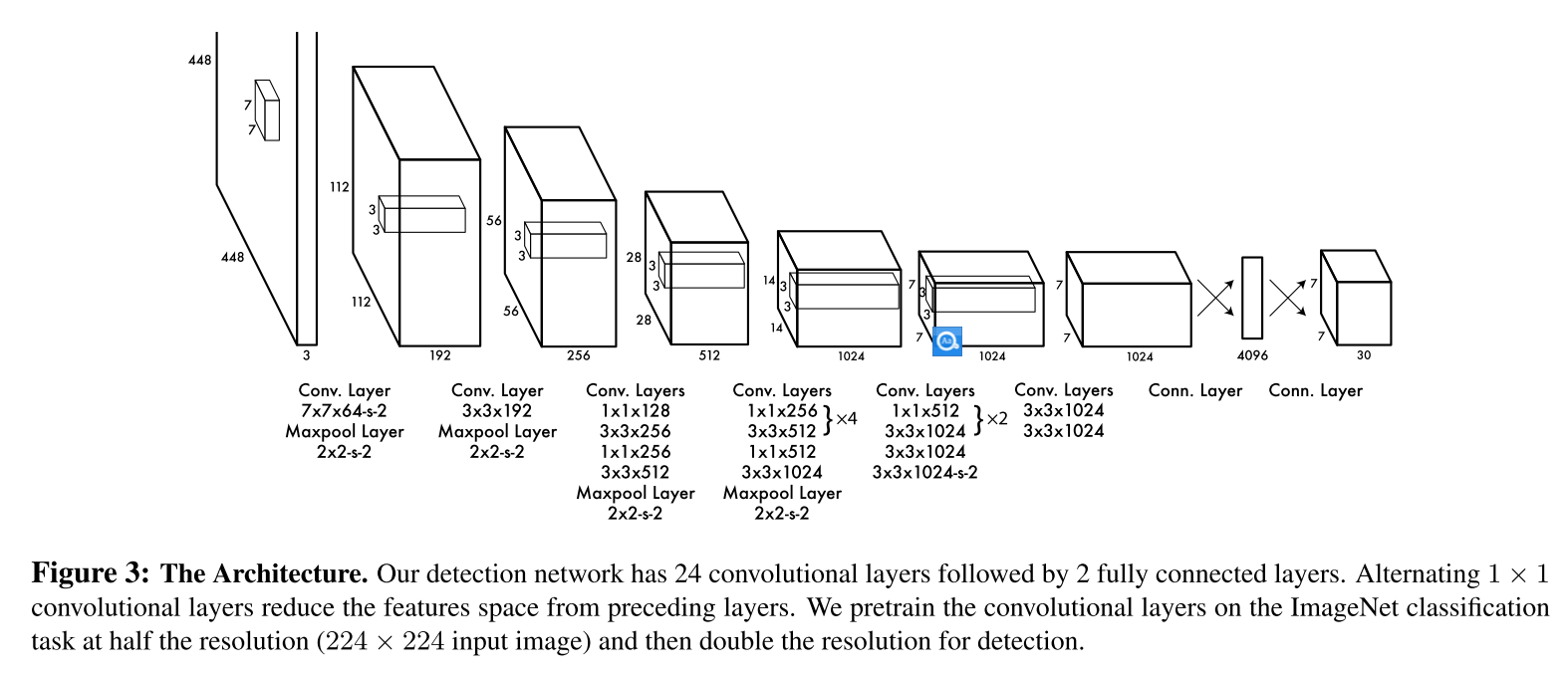
整个YOLO的结构如上图,受GoogLeNet启发,但并没有直接用Inception模块,而是用1x1的降维层+3x3的卷积层来替代。
YOLO一共24个卷积层用于提取特征,加上用于分类和定位的2个全连接层。最后的输出为 $7·7·30$ 与上节基本思路里的输出设计是符合的。
训练细节
- 对YOLO网络的前20个卷积层进行预训练
- 在ImageNet-1000上训练
- 在卷积层后简单加上平均池化层和全连接层
- 在预训练的20个卷积层后加上随机初始化的4个卷积层和2个全连接层进行目标检测任务的训练
- 将图像输入尺寸从224x224增加到448x448,从而获得更细粒度的视觉信息(尺寸与速度之间的权衡?)
- 将BBox的$w,h$和offset都进行归一化
- 除最后一层使用线性激活函数,其它层都使用文中2.2节描述的leaky rectified linear activation
- 计算Loss分别,由IoU计算定位误差时,对BBox是否包含物体的两种情况,分别设置了两个参数 $\lambda_{coord}=5$ 和 $\lambda_{noobj}=0.5$ 。
- 2.2节最后还写到了
- 训练参数的设置
- 学习率的设置:冷启动->慢慢增大->逐阶段递减
- 过拟合的措施:Dropout=0.5
- 数据增广:随机缩放+随机旋转+随机曝光+在HSV空间增加饱和度