SSD 论文阅读笔记
SSD 论文阅读笔记
资料
SSD: Single Shot MultiBox Detector
原文下载:PDF
中文翻译:SSD: Single Shot MultiBox Detector翻译(包括正式版和预印版)(对原文作部分理解性修改)
参考PPT :一份俄语PPT
笔记
SSD,Single Shot MultiBox Detector,单发多框检测,属于one stage范畴。比YOLO(V1)快又准,比Faster R-CNN准确度相当。
SSD使用的是anchor机制(论文中称之为default box),在主干网络(原始网络截断分类层)的特征图上,使用卷积滤波器预测anchor box的分类置信度和目标边界框的偏移量。
SSD的模型
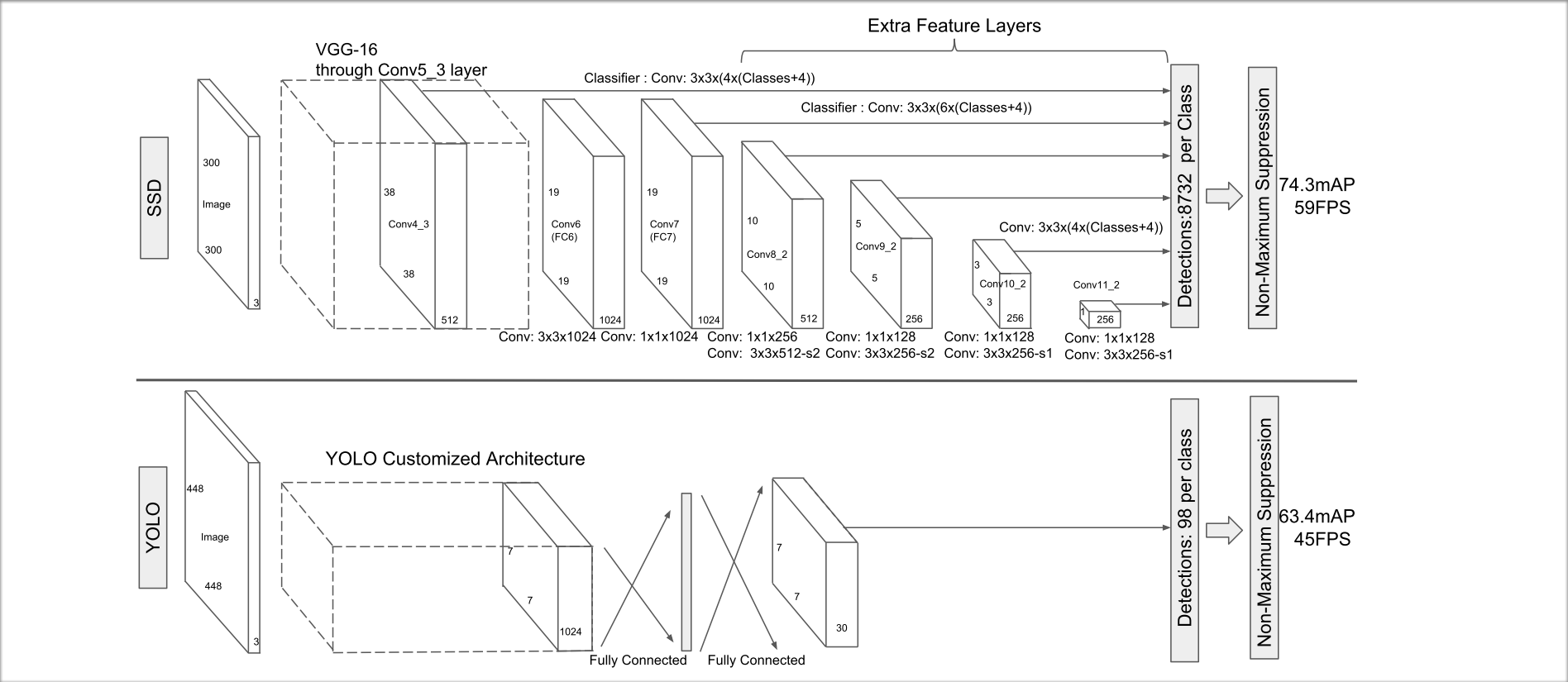
论文中的SSD模型结构和YOLO模型结构的对比图:
俄语PPT中的SSD-300模型图,我认为更直观反映SSD的多尺度检测和NMS选择:
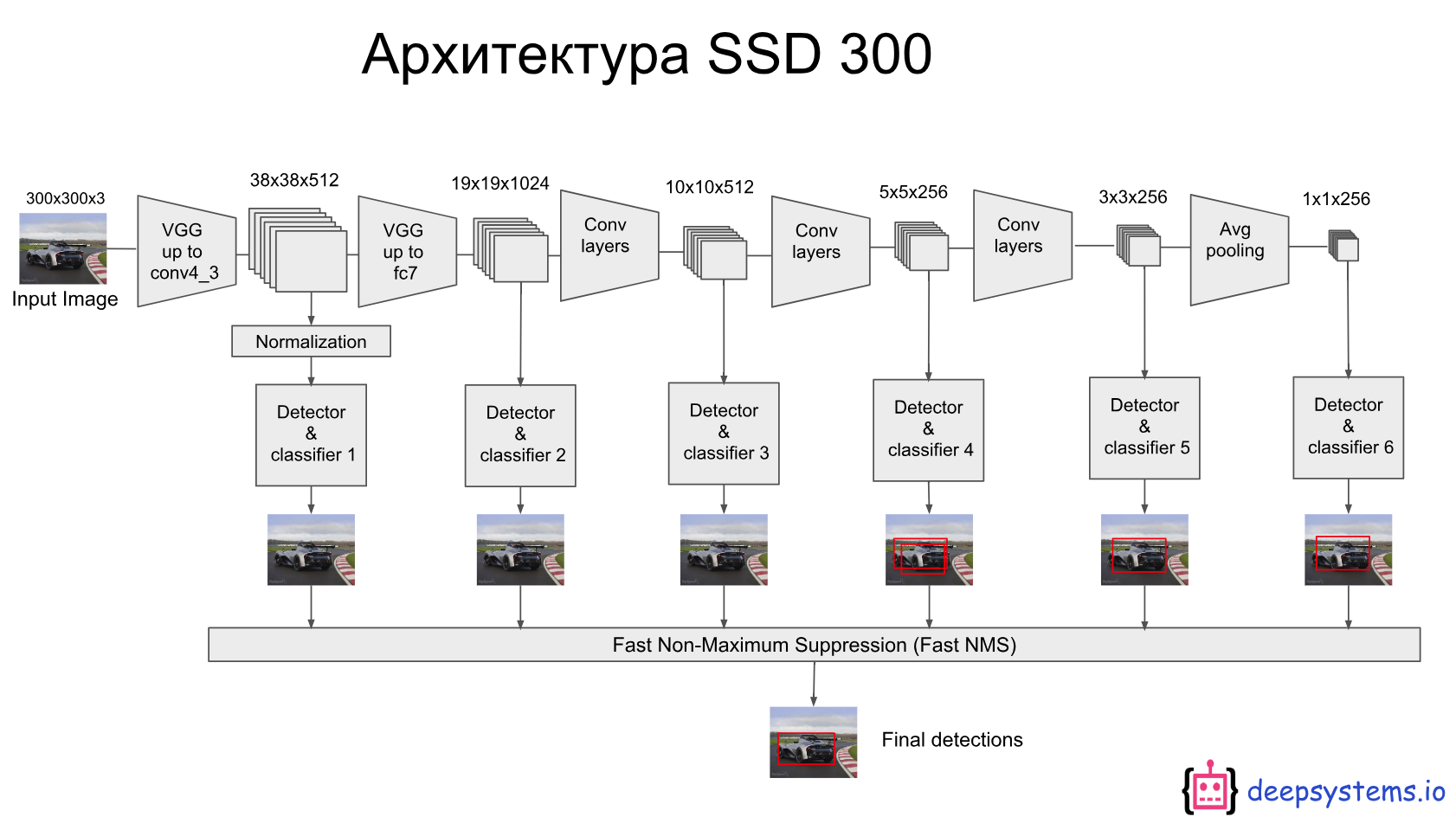
模型中的几个关键点:
多尺度的特征图检测
如上图SSD 300的模型图,在几个特征图上(即主干网络之后的卷积特征层),依次划分了38x38、19x19、10x10、5x5、3x3和1x1个grid cell(cell对应default box/anchor),每个anchor用于预测分类和目标边界框。如38x38、19x19,每个单元的感受野较小,更适合检测尺寸较小的目标,反之,如5x5、3x3等,每个单元的感受野较大,更适合检测尺寸较大的目标。
使用卷积滤波器进行检测:
如上图SSD 300的模型图,在每一个特征图上(设大小 m*n,通道为p),使用3x3xp的卷积核进行滤波,则在进行核运算的每点,都得到一个输出值,要么用于分类置信度,要么用于目标边界框的偏移量。下图举例说明,中间的3x3卷积核用于目标边界框的回归预测,右侧的3x3卷积核用于目标分类预测。

默认框(anchor)与宽高比
默认框以卷积的方式平铺特征映射,以便每个框相对于其对应单元的位置是固定的。在每个特征映射单元中,我们预测相对于单元格中的默认框形状的偏移,以及指出这些框中每个框存在的详细类别的每类评分。具体来说,对于在给定位置的k个框中每个框,我们计算c类分数和相对于原始默认框的4个偏移量。这使得在特征图中的每个位置需要总共(c+4)·k个滤波器,对于m×n特征图产生(c+4)·k·m·n个输出。
同时,采用不同宽高比的anchor,有效离散出可能的目标边界框形状空间,提升模型的性能。
如上图左侧所示,5x5的特征图,可以有25个正常anchor(宽高比为1);
通过采用不同宽高比的anchor,如宽高比为2或0.5的anchor,则增加两类anchor,共计25·3=75个anchor。
SSD的训练
训练中的几个关键点和细节:
匹配策略(匹配问题)
匹配问题指的是,在训练过程中,将真值标签(Ground Truth,包含分类和边界框位置)合理地匹配给每个特征图的anchor boxes中,将真值标签分配好后,才可以进行训练的误差计算。
论文提出了两步走的方式:计算真值标签与特征图中各个anchor的Jaccard值(也叫IoU/交并比)。第一步将真值标签分配给重叠最好的anchor,确保每个真值标签都有一个匹配的默认值;第二步,在剩余anchor中继续筛选,挑选出与真值标签Jaccard值高于阈值的anchor,将它与对应的真值标签相匹配;其余的anchor抛弃不管。
训练目标(损失函数)
目标检测的损失函数分为两个:一个是分类损失,一般用二分类交叉熵损失函数(BCE);一个是边界框的定位损失,这是个回归问题,一般使用L1 Loss或者平滑L1 Loss(Smooth L1 Loss)。对每个anchor进行计算loss,累加,并反向传播。
默认框(anchor)的尺度和宽高比选择
如上节所说,采用不同宽高比的anchor,能有效离散出可能的目标边界框形状空间,提升模型的性能。
同时,不同特征图的anchor具有不同的感受野,通过组合许多特征图在各个位置的不同尺寸和不同宽高比的anchor的预测,增加了更多样化的预测集合,覆盖到更多的输入对象输入尺寸和形状,增强模型的泛化性能。
论文推荐了如下的anchor比例计算的方式,原文:

翻译摘抄自《SSD: Single Shot MultiBox Detector翻译》:

Hard negative mining(硬负挖掘??)
在之前的匹配策略之后,许多anchor是负样本,没有匹配到目标(即背景),特别是当不同尺寸和宽高比增加anchor数目之后,负样本的比例会很大。正负样本之间的不平衡会影响训练效果。但是SSD的机制是,不采用所有的负样本,而是通过置信度来排序,删除置信度低的样本,这样能维持正负样本的比例在1:3之间。
数据增强
论文在训练小节和实验分析小节都强调了数据增强的至关重要的作用。论文采用了如下的增强的步骤。为了使模型对于各种输入对象大小和形状更加鲁棒,每个训练图像通过以下选项之一随机采样:
- 使用整个原始输入图像
- 采样一个片段,使对象最小的jaccard重叠值为0.1,0.3,0.5,0.7或0.9。
- 随机采样一个片段
每个采样片段的大小为原始图像大小的[0.1,1],横宽比在1/2和2之间。如果真实标签框中心在采样片段内,则保留重叠部分。在上述采样步骤之后,还采用一些光度失真操作,将每个采样片段调整为固定大小并以0.5的概率水平翻转。
SSD 与 小目标
论文中也提到了SSD适合检测大目标,在小目标的检测准确率上比不上Faster R-CNN。
解决方式之一就是提高输入图像的分辨率,让anchor的感受野更小。
解决方式之二就是数据增强步骤中,采用zoom out(缩小)操作。
参考:
SSD: Single Shot MultiBox Detector翻译(包括正式版和预印版)(对原文作部分理解性修改)
论文阅读《SSD: Single Shot MultiBox Detector》
文中图像来自论文原文和开头指出的俄语PPT(不知道出处)。