Fast.ai Lesson 8: 目标检测 fast.ai 0.7版本
Pytorch 0.3版本
1 2 3 4 5 6 7 %matplotlib inline %config InlineBackend.figure_format="retina" %config InlineBackend.rc = {"figure.figsize" : (7.5 ,4.5 )} %reload_ext autoreload %autoreload 2
1 2 3 4 5 6 7 8 from fastai.conv_learner import *from fastai.dataset import *from pathlib import Pathimport jsonfrom PIL import ImageDraw, ImageFontfrom matplotlib import patches, patheffects
1 2 torch.cuda.set_device(0 )
Pascal VOC 数据集 官网 The PASCAL Visual Object Classes Homepage
数据集镜像网站 Pascal VOC Dataset Mirror
Json格式的标注文件更便于处理 https://storage.googleapis.com/coco-dataset/external/PASCAL_VOC.zip
这次实验用的是2007版本的数据集。
构建关系字典 1 2 3 PATH = Path('data/pascal2007' ) list (PATH.iterdir())
[PosixPath('data/pascal2007/tmp'),
PosixPath('data/pascal2007/models'),
PosixPath('data/pascal2007/pascal_test2007.json'),
PosixPath('data/pascal2007/raw'),
PosixPath('data/pascal2007/pascal_train2007.json'),
PosixPath('data/pascal2007/pascal_val2007.json'),
PosixPath('data/pascal2007/VOCdevkit'),
PosixPath('data/pascal2007/pascal_train2012.json'),
PosixPath('data/pascal2007/pascal_val2012.json')]
1 2 3 trn_j = json.load((PATH/'pascal_train2007.json' ).open ()) trn_j.keys()
dict_keys(['images', 'type', 'annotations', 'categories'])
1 2 IMAGES,ANNOTATIONS,CATEGORIES = ['images' , 'annotations' , 'categories' ]
[{'file_name': '000012.jpg', 'height': 333, 'width': 500, 'id': 12},
{'file_name': '000017.jpg', 'height': 364, 'width': 480, 'id': 17},
{'file_name': '000023.jpg', 'height': 500, 'width': 334, 'id': 23},
{'file_name': '000026.jpg', 'height': 333, 'width': 500, 'id': 26},
{'file_name': '000032.jpg', 'height': 281, 'width': 500, 'id': 32}]
[{'segmentation': [[155, 96, 155, 270, 351, 270, 351, 96]],
'area': 34104,
'iscrowd': 0,
'image_id': 12,
'bbox': [155, 96, 196, 174],
'category_id': 7,
'id': 1,
'ignore': 0},
{'segmentation': [[184, 61, 184, 199, 279, 199, 279, 61]],
'area': 13110,
'iscrowd': 0,
'image_id': 17,
'bbox': [184, 61, 95, 138],
'category_id': 15,
'id': 2,
'ignore': 0}]
[{'supercategory': 'none', 'id': 1, 'name': 'aeroplane'},
{'supercategory': 'none', 'id': 2, 'name': 'bicycle'},
{'supercategory': 'none', 'id': 3, 'name': 'bird'},
{'supercategory': 'none', 'id': 4, 'name': 'boat'},
{'supercategory': 'none', 'id': 5, 'name': 'bottle'}]
1 2 3 4 5 6 7 8 9 FILE_NAME,ID,IMG_ID,CAT_ID,BBOX = ['file_name' ,'id' ,'image_id' ,'category_id' ,'bbox' ] cats = {o[ID]:o['name' ] for o in trn_j[CATEGORIES]} trn_fns = {o[ID]:o[FILE_NAME] for o in trn_j[IMAGES]} trn_ids = {o[ID] for o in trn_j[IMAGES]}
1 2 list ((PATH/'VOCdevkit' /'VOC2007' ).iterdir())
[PosixPath('data/pascal2007/VOCdevkit/VOC2007/SegmentationObject'),
PosixPath('data/pascal2007/VOCdevkit/VOC2007/JPEGImages'),
PosixPath('data/pascal2007/VOCdevkit/VOC2007/ImageSets'),
PosixPath('data/pascal2007/VOCdevkit/VOC2007/SegmentationClass'),
PosixPath('data/pascal2007/VOCdevkit/VOC2007/Annotations')]
1 2 JPEGS = "VOCdevkit/VOC2007/JPEGImages"
1 2 3 IMG_PATH = PATH/JPEGS list (IMG_PATH.iterdir())[:5 ]
[PosixPath('data/pascal2007/VOCdevkit/VOC2007/JPEGImages/005601.jpg'),
PosixPath('data/pascal2007/VOCdevkit/VOC2007/JPEGImages/009666.jpg'),
PosixPath('data/pascal2007/VOCdevkit/VOC2007/JPEGImages/008026.jpg'),
PosixPath('data/pascal2007/VOCdevkit/VOC2007/JPEGImages/004041.jpg'),
PosixPath('data/pascal2007/VOCdevkit/VOC2007/JPEGImages/008781.jpg')]
1 2 3 im0_d = trn_j[IMAGES][0 ] im0_d[FILE_NAME],im0_d[ID]
('000012.jpg', 12)
BBox转换 Python中的collections.defaultdict()可以有效解决字典使用中的默认值设置问题。
参考链接: Python中collections.defaultdict()使用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 def hw_bb (bb ): return np.array([bb[1 ], bb[0 ], bb[3 ]+bb[1 ]-1 , bb[2 ]+bb[0 ]-1 ]) trn_anno = collections.defaultdict(lambda : []) for o in trn_j[ANNOTATIONS]: if not o['ignore' ]: bbx = o[BBOX] bbx = hw_bb(bbx) trn_anno[o[IMG_ID]].append((bbx, o[CAT_ID])) len (trn_anno)
2501
1 2 3 im_a = trn_anno[im0_d[ID]]; im_a
[(array([ 96, 155, 269, 350]), 7)]
(array([ 96, 155, 269, 350]), 7)
'car'
[(array([ 61, 184, 198, 278]), 15), (array([ 77, 89, 335, 402]), 13)]
('person', 'horse')
有些图表库在绘制时采用的跟VOC的格式相同,所以也可以添加一个函数用于,将左上角/右下角转换成宽和高。
1 2 bb_voc = [155 , 96 , 196 , 174 ] bb_fastai = hw_bb(bb_voc)
1 2 3 def bb_hw (a ): return np.array([a[1 ],a[0 ],a[3 ]-a[1 ]+1 ,a[2 ]-a[0 ]+1 ])
1 f'expected: {bb_voc} , actual: {bb_hw(bb_fastai)} '
'expected: [155, 96, 196, 174], actual: [155 96 196 174]'
实现图像标注显示 fast.ai库中打开图像是通过opencv打开的,效率比PIL方式快很多。
OpenCV打开的速度比Torchvision快5-10倍。同时,fast.ai快的原因不是采用多进程而是采用多线程进行数据增强处理。
坚持用Opencv来做数据增强,而不要采用TorchVision或者Pillow。
1 2 im = open_image(IMG_PATH/im0_d[FILE_NAME])
Matplotlib中的plt.subplots是一个面向对象的非常实用的工具。
1 2 3 4 5 6 7 def show_img (im, figsize=None , ax=None ): if not ax: fig,ax = plt.subplots(figsize=figsize) ax.imshow(im) ax.get_xaxis().set_visible(False ) ax.get_yaxis().set_visible(False ) return ax
fast.ai的作者的创意:无视背景色的前景文本和矩形框,加一个包边处理。
1 2 3 4 def draw_outline (o, lw ): o.set_path_effects([patheffects.Stroke( linewidth=lw, foreground='black' ), patheffects.Normal()])
1 2 3 4 def draw_rect (ax, b ): patch = ax.add_patch(patches.Rectangle(b[:2 ], *b[-2 :], fill=False , edgecolor='white' , lw=2 )) draw_outline(patch, 4 )
1 2 3 4 5 def draw_text (ax, xy, txt, sz=14 ): text = ax.text(*xy, txt, verticalalignment='top' , color='white' , fontsize=sz, weight='bold' ) draw_outline(text, 1 )
1 2 3 4 ax = show_img(im) b = bb_hw(im0_a[0 ]) draw_rect(ax, b) draw_text(ax, b[:2 ], cats[im0_a[1 ]])
1 2 3 4 5 6 7 def draw_im (im, ann ): ax = show_img(im, figsize=(16 ,8 )) for b,c in ann: b = bb_hw(b) draw_rect(ax, b) draw_text(ax, b[:2 ], cats[c], sz=16 )
1 2 3 4 5 6 def draw_idx (i ): im_a = trn_anno[i] im = open_image(IMG_PATH/trn_fns[i]) print (im.shape) draw_im(im, im_a)
(500, 333, 3)
ERROR:root:No traceback has been produced, nothing to debug.
(364, 480, 3)
最大目标分类器 实现图像中最大的目标的分类。下一步再进行定位。
分类器的训练集是将VOC数据集中最大标注面积的物体作为整幅图像的分类目标来做训练的。
创建分类数据集 1 2 3 4 5 6 7 def get_lrg (a,b ): if not b: raise Exception("b is null" ) b = sorted (b, key=lambda x:np.product(x[0 ][-2 :] - x[0 ][:2 ]), reverse=True ) return b[0 ]
lambda可以用来构建简单的函数,下面这个函数用lambda函数来表示对标注序列按照bbox面积进行排序
1 2 trn_lrg_anno = {a: get_lrg(a,b) for a,b in trn_anno.items()}
1 2 3 4 5 b,c = trn_lrg_anno[17 ] b = bb_hw(b) ax = show_img(open_image(IMG_PATH/trn_fns[17 ]), figsize=(5 ,10 )) draw_rect(ax,b) draw_text(ax,b[:2 ],cats[c],sz=16 )
fast.ai库中构建许多创建数据集的方式,其中一个就是从CSV文件中构建数据集。
所以,与其自己定义Dataset并构建数据集,不如直接将已有的数据保存到csv文件中,再调用API直接进行dataset和dataloader的生成
1 2 3 (PATH/'tmp' ).mkdir(exist_ok=True ) CSV = PATH/'tmp/lrg.csv'
1 2 3 4 df = pd.DataFrame({'fn' :[trn_fns[o] for o in trn_ids], 'cat' :[cats[trn_lrg_anno[o][1 ]] for o in trn_ids]}, columns=['fn' ,'cat' ]) df.to_csv(CSV, index=False )
分类模型和训练 1 2 3 4 f_model = resnet34 sz = 224 bs = 64
之所以要用CropType.NO是因为不像ImageNet那种数据(图像中主要目标在画面中心),Pascal数据集中很多情况下,目标又小,且在画面边缘,因此centerCrop会影响数据增强的实际效果。
1 2 3 tfms = tfms_from_model(f_model=f_model, sz=sz, aug_tfms=transforms_side_on, crop_type=CropType.NO) md = ImageClassifierData.from_csv(path=PATH, folder=JPEGS, csv_fname=CSV, tfms=tfms, bs=bs)
1 x,y = next (iter (md.val_dl))
所有ImageNet预训练的模型,都对数据输入做了Normalize处理(0均值1方差),因此想要得到正常的图像,需要进行逆归一化处理。
fast.ai提供了denorm方法。同时记得将GPU中的数据移到CPU的numpy中。
1 show_img(md.val_ds.denorm(to_np(x))[0 ]);
1 2 3 learn = ConvLearner.pretrained(f=f_model, data=md, metrics=[accuracy]) learn.opt_fn = optim.Adam
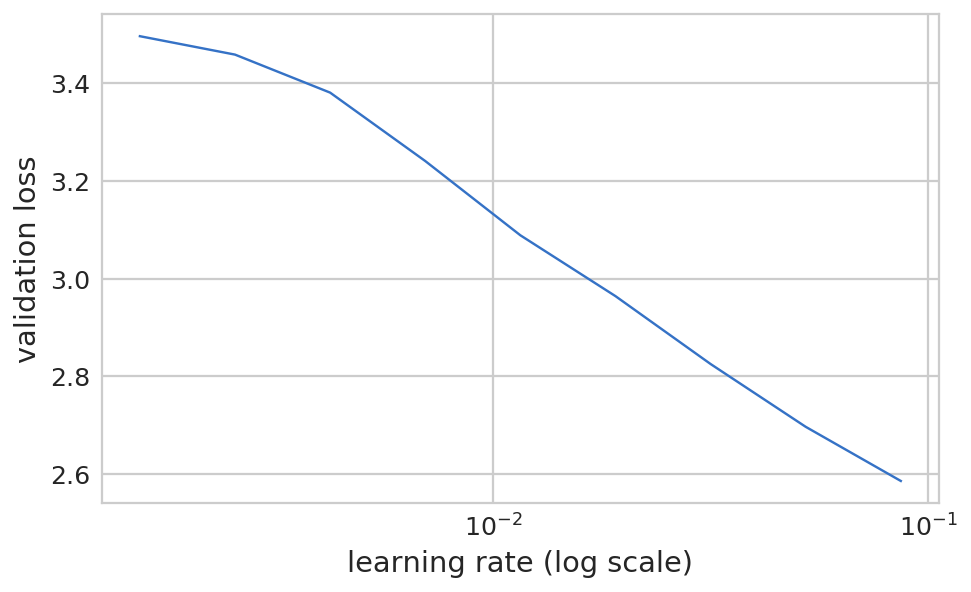
1 2 3 lrf=learn.lr_find(1e-5 ,100 ) learn.sched.plot()
HBox(children=(IntProgress(value=0, description='Epoch', max=1), HTML(value='')))
78%|███████▊ | 25/32 [00:05<00:00, 7.78it/s, loss=5.06]
1 learn.sched.plot(n_skip=5 , n_skip_end=1 )
1 learn.fit(lr, 1 , cycle_len=1 )
HBox(children=(IntProgress(value=0, description='Epoch', max=1), HTML(value='')))
epoch trn_loss val_loss accuracy
0 1.252253 0.738965 0.766
[array([0.73897]), 0.7660000019073486]
1 2 lrs = np.array([lr/1000 ,lr/100 ,lr])
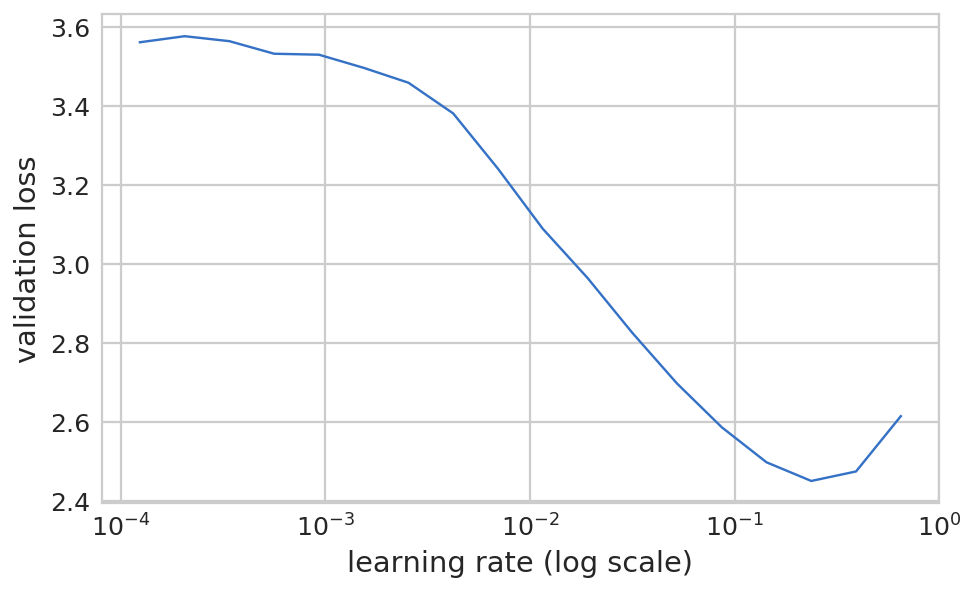
1 2 lrf=learn.lr_find(start_lr=lrs/1000 ) learn.sched.plot(1 )
HBox(children=(IntProgress(value=0, description='Epoch', max=1), HTML(value='')))
84%|████████▍ | 27/32 [00:07<00:01, 4.02it/s, loss=2.05]
1 learn.fit(lrs/5 , 1 , cycle_len=1 )
HBox(children=(IntProgress(value=0, description='Epoch', max=1), HTML(value='')))
epoch trn_loss val_loss accuracy
0 0.761318 0.678066 0.772
[array([0.67807]), 0.7720000019073486]
准确率不高可能是因为图像中有很多明显的目标,所以没有单分类时的图像识别的准确率高
1 learn.fit(lrs/5 , 1 , cycle_len=2 )
HBox(children=(IntProgress(value=0, description='Epoch', max=2), HTML(value='')))
epoch trn_loss val_loss accuracy
0 0.598608 0.650308 0.794
1 0.429849 0.63418 0.798
[array([0.63418]), 0.7980000004768372]
1 2 3 learn.save('clas_one' ) learn.load('clas_one' )
分类测试 1 2 3 4 5 x,y = next (iter (md.val_dl)) probs = F.softmax(predict_batch(learn.model, x), -1 ) X,preds = to_np(x), to_np(probs) preds = np.argmax(preds, -1 )
1 2 3 4 5 6 7 8 fig,axes = plt.subplots(3 ,4 , figsize = (16 ,12 )) for i,ax in enumerate (axes.flat): ima = md.val_ds.denorm(x)[i] b = md.classes[preds[i]] ax = show_img(ima, ax = ax) draw_text(ax, (0 ,0 ),b) plt.tight_layout
WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
<function matplotlib.pyplot.tight_layout(pad=1.08, h_pad=None, w_pad=None, rect=None)>
BBox预测 寻找最大物体的bounding box, 只是用简单的回归预测,(4输出)。
创建BBox的CSV文件 1 2 BB_CSV = PATH/'tmp/bb.csv'
1 2 3 4 5 bb = np.array([trn_lrg_anno[o][0 ] for o in trn_ids]) bbs = [' ' .join(str (p) for p in o) for o in bb] df = pd.DataFrame({'fn' :[trn_fns[o] for o in trn_ids], 'bbox' : bbs}, columns=['fn' ,'bbox' ]) df.to_csv(BB_CSV, index=False )
1 BB_CSV.open ().readlines()[:5 ]
['fn,bbox\n',
'008197.jpg,186 450 226 496\n',
'008199.jpg,84 363 374 498\n',
'008202.jpg,110 190 371 457\n',
'008203.jpg,187 37 359 303\n']
模型和训练 1 2 3 4 f_model = resnet34 sz = 224 bs = 64
Data Augmentation 1 2 3 4 augs = [RandomFlip(), RandomRotate(30 ), RandomLighting(0.1 ,0.1 )]
设置continuous=True是为了设置fastai处理一个回归问题,这个状态下,标签数据将不会被热编码。同时采用MSE作为默认的评估函数。
设置CropType.NO是因为想要将矩形的图像压成正方形的图像,而不是采用center cropping, 采用center cropping可能会丢失目标。因为这是多目标图像,而不是类似ImageNet的单目标图像。
1 2 tfms = tfms_from_model(f_model=f_model, sz=sz, aug_tfms=augs, crop_type=CropType.NO) md = ImageClassifierData.from_csv(path=PATH, folder=JPEGS, csv_fname=BB_CSV, tfms=tfms, continuous=True , bs= bs)
1 2 3 4 5 6 7 8 9 10 idx = 5 fig,axes = plt.subplots(ncols=3 ,nrows=3 ,figsize=(9 ,9 )) for i,ax in enumerate (axes.flat): x,y = next (iter (md.aug_dl)) ima = md.val_ds.denorm(to_np(x))[idx] b = bb_hw(to_np(y[idx])) print (b) show_img(ima,ax=ax) draw_rect(ax, b)
[ 51. 102. 449. 222.]
[ 51. 102. 449. 222.]
[ 51. 102. 449. 222.]
[ 51. 102. 449. 222.]
[ 51. 102. 449. 222.]
[ 51. 102. 449. 222.]
[ 51. 102. 449. 222.]
[ 51. 102. 449. 222.]
[ 51. 102. 449. 222.]
上图可知框的增强方式不可以,扩增的bbox并不能包围住目标。
按照fast.ai作者的说法是需要指定transform的类型为坐标类型(tfmType.COORD)
1 2 3 4 augs = [RandomFlip(tfm_y=TfmType.COORD), RandomRotate(30 , tfm_y=TfmType.COORD), RandomLighting(0.1 ,0.1 , tfm_y=TfmType.COORD)]
1 2 tfms = tfms_from_model(f_model=f_model, sz=sz, aug_tfms=augs, crop_type=CropType.NO, tfm_y=TfmType.COORD) md = ImageClassifierData.from_csv(path=PATH, folder=JPEGS, csv_fname=BB_CSV, tfms=tfms, continuous=True , bs= bs)
1 2 3 4 5 6 7 8 9 10 idx = 5 fig,axes = plt.subplots(ncols=3 ,nrows=3 ,figsize=(9 ,9 )) for i,ax in enumerate (axes.flat): x,y = next (iter (md.aug_dl)) ima = md.val_ds.denorm(to_np(x))[idx] b = bb_hw(to_np(y[idx])) print (b) show_img(ima,ax=ax) draw_rect(ax, b)
[ 0. 59. 204. 164.]
[ 18. 58. 206. 165.]
[ 11. 42. 213. 181.]
[ 1. 69. 199. 146.]
[ 7. 31. 217. 192.]
[ 0. 7. 204. 216.]
[ 0. 27. 204. 196.]
[ 0. 45. 203. 178.]
[ 20. 0. 204. 223.]
这样的增强方式是对的。
1 2 3 4 5 6 7 8 tfm_y = TfmType.COORD augs = [RandomFlip(tfm_y=tfm_y), RandomRotate(3 , p=0.5 , tfm_y=tfm_y), RandomLighting(0.05 ,0.05 , tfm_y=tfm_y)] tfms = tfms_from_model(f_model, sz, crop_type=CropType.NO, tfm_y=tfm_y, aug_tfms=augs) md = ImageClassifierData.from_csv(PATH, JPEGS, BB_CSV, tfms=tfms, bs=bs, continuous=True )
自定义 网络层 fast.ai 允许使用custom_head在卷积层之后添加自定义模块,而不是默认的adaptive pooling层和全连接层。
在本实验中,由于需要知道每个格点的activation强度,因此不能做池化。
最后一层有四个activations, 每个bbox的坐标。由于目标是连续的,而不是分类的,所以所以MSE损失函数并无帮助。
25088
1 2 3 4 head_reg4 = nn.Sequential(Flatten(), nn.Linear(25088 , 4 )) learn = ConvLearner.pretrained(f_model, md, custom_head=head_reg4) learn.opt_fn = optim.Adam learn.crit = nn.L1Loss()
OrderedDict([('Conv2d-1',
OrderedDict([('input_shape', [-1, 3, 224, 224]),
('output_shape', [-1, 64, 112, 112]),
('trainable', False),
('nb_params', 9408)])),
('BatchNorm2d-2',
OrderedDict([('input_shape', [-1, 64, 112, 112]),
('output_shape', [-1, 64, 112, 112]),
('trainable', False),
('nb_params', 128)])),
('ReLU-3',
OrderedDict([('input_shape', [-1, 64, 112, 112]),
('output_shape', [-1, 64, 112, 112]),
('nb_params', 0)])),
('MaxPool2d-4',
OrderedDict([('input_shape', [-1, 64, 112, 112]),
('output_shape', [-1, 64, 56, 56]),
('nb_params', 0)])),
('Conv2d-5',
OrderedDict([('input_shape', [-1, 64, 56, 56]),
('output_shape', [-1, 64, 56, 56]),
('trainable', False),
('nb_params', 36864)])),
('BatchNorm2d-6',
OrderedDict([('input_shape', [-1, 64, 56, 56]),
('output_shape', [-1, 64, 56, 56]),
('trainable', False),
('nb_params', 128)])),
('ReLU-7',
OrderedDict([('input_shape', [-1, 64, 56, 56]),
('output_shape', [-1, 64, 56, 56]),
('nb_params', 0)])),
('Conv2d-8',
OrderedDict([('input_shape', [-1, 64, 56, 56]),
('output_shape', [-1, 64, 56, 56]),
('trainable', False),
('nb_params', 36864)])),
('BatchNorm2d-9',
OrderedDict([('input_shape', [-1, 64, 56, 56]),
('output_shape', [-1, 64, 56, 56]),
('trainable', False),
('nb_params', 128)])),
('ReLU-10',
OrderedDict([('input_shape', [-1, 64, 56, 56]),
('output_shape', [-1, 64, 56, 56]),
('nb_params', 0)])),
('BasicBlock-11',
OrderedDict([('input_shape', [-1, 64, 56, 56]),
('output_shape', [-1, 64, 56, 56]),
('nb_params', 0)])),
('Conv2d-12',
OrderedDict([('input_shape', [-1, 64, 56, 56]),
('output_shape', [-1, 64, 56, 56]),
('trainable', False),
('nb_params', 36864)])),
('BatchNorm2d-13',
OrderedDict([('input_shape', [-1, 64, 56, 56]),
('output_shape', [-1, 64, 56, 56]),
('trainable', False),
('nb_params', 128)])),
('ReLU-14',
OrderedDict([('input_shape', [-1, 64, 56, 56]),
('output_shape', [-1, 64, 56, 56]),
('nb_params', 0)])),
('Conv2d-15',
OrderedDict([('input_shape', [-1, 64, 56, 56]),
('output_shape', [-1, 64, 56, 56]),
('trainable', False),
('nb_params', 36864)])),
('BatchNorm2d-16',
OrderedDict([('input_shape', [-1, 64, 56, 56]),
('output_shape', [-1, 64, 56, 56]),
('trainable', False),
('nb_params', 128)])),
('ReLU-17',
OrderedDict([('input_shape', [-1, 64, 56, 56]),
('output_shape', [-1, 64, 56, 56]),
('nb_params', 0)])),
('BasicBlock-18',
OrderedDict([('input_shape', [-1, 64, 56, 56]),
('output_shape', [-1, 64, 56, 56]),
('nb_params', 0)])),
('Conv2d-19',
OrderedDict([('input_shape', [-1, 64, 56, 56]),
('output_shape', [-1, 64, 56, 56]),
('trainable', False),
('nb_params', 36864)])),
('BatchNorm2d-20',
OrderedDict([('input_shape', [-1, 64, 56, 56]),
('output_shape', [-1, 64, 56, 56]),
('trainable', False),
('nb_params', 128)])),
('ReLU-21',
OrderedDict([('input_shape', [-1, 64, 56, 56]),
('output_shape', [-1, 64, 56, 56]),
('nb_params', 0)])),
('Conv2d-22',
OrderedDict([('input_shape', [-1, 64, 56, 56]),
('output_shape', [-1, 64, 56, 56]),
('trainable', False),
('nb_params', 36864)])),
('BatchNorm2d-23',
OrderedDict([('input_shape', [-1, 64, 56, 56]),
('output_shape', [-1, 64, 56, 56]),
('trainable', False),
('nb_params', 128)])),
('ReLU-24',
OrderedDict([('input_shape', [-1, 64, 56, 56]),
('output_shape', [-1, 64, 56, 56]),
('nb_params', 0)])),
('BasicBlock-25',
OrderedDict([('input_shape', [-1, 64, 56, 56]),
('output_shape', [-1, 64, 56, 56]),
('nb_params', 0)])),
('Conv2d-26',
OrderedDict([('input_shape', [-1, 64, 56, 56]),
('output_shape', [-1, 128, 28, 28]),
('trainable', False),
('nb_params', 73728)])),
('BatchNorm2d-27',
OrderedDict([('input_shape', [-1, 128, 28, 28]),
('output_shape', [-1, 128, 28, 28]),
('trainable', False),
('nb_params', 256)])),
('ReLU-28',
OrderedDict([('input_shape', [-1, 128, 28, 28]),
('output_shape', [-1, 128, 28, 28]),
('nb_params', 0)])),
('Conv2d-29',
OrderedDict([('input_shape', [-1, 128, 28, 28]),
('output_shape', [-1, 128, 28, 28]),
('trainable', False),
('nb_params', 147456)])),
('BatchNorm2d-30',
OrderedDict([('input_shape', [-1, 128, 28, 28]),
('output_shape', [-1, 128, 28, 28]),
('trainable', False),
('nb_params', 256)])),
('Conv2d-31',
OrderedDict([('input_shape', [-1, 64, 56, 56]),
('output_shape', [-1, 128, 28, 28]),
('trainable', False),
('nb_params', 8192)])),
('BatchNorm2d-32',
OrderedDict([('input_shape', [-1, 128, 28, 28]),
('output_shape', [-1, 128, 28, 28]),
('trainable', False),
('nb_params', 256)])),
('ReLU-33',
OrderedDict([('input_shape', [-1, 128, 28, 28]),
('output_shape', [-1, 128, 28, 28]),
('nb_params', 0)])),
('BasicBlock-34',
OrderedDict([('input_shape', [-1, 64, 56, 56]),
('output_shape', [-1, 128, 28, 28]),
('nb_params', 0)])),
('Conv2d-35',
OrderedDict([('input_shape', [-1, 128, 28, 28]),
('output_shape', [-1, 128, 28, 28]),
('trainable', False),
('nb_params', 147456)])),
('BatchNorm2d-36',
OrderedDict([('input_shape', [-1, 128, 28, 28]),
('output_shape', [-1, 128, 28, 28]),
('trainable', False),
('nb_params', 256)])),
('ReLU-37',
OrderedDict([('input_shape', [-1, 128, 28, 28]),
('output_shape', [-1, 128, 28, 28]),
('nb_params', 0)])),
('Conv2d-38',
OrderedDict([('input_shape', [-1, 128, 28, 28]),
('output_shape', [-1, 128, 28, 28]),
('trainable', False),
('nb_params', 147456)])),
('BatchNorm2d-39',
OrderedDict([('input_shape', [-1, 128, 28, 28]),
('output_shape', [-1, 128, 28, 28]),
('trainable', False),
('nb_params', 256)])),
('ReLU-40',
OrderedDict([('input_shape', [-1, 128, 28, 28]),
('output_shape', [-1, 128, 28, 28]),
('nb_params', 0)])),
('BasicBlock-41',
OrderedDict([('input_shape', [-1, 128, 28, 28]),
('output_shape', [-1, 128, 28, 28]),
('nb_params', 0)])),
('Conv2d-42',
OrderedDict([('input_shape', [-1, 128, 28, 28]),
('output_shape', [-1, 128, 28, 28]),
('trainable', False),
('nb_params', 147456)])),
('BatchNorm2d-43',
OrderedDict([('input_shape', [-1, 128, 28, 28]),
('output_shape', [-1, 128, 28, 28]),
('trainable', False),
('nb_params', 256)])),
('ReLU-44',
OrderedDict([('input_shape', [-1, 128, 28, 28]),
('output_shape', [-1, 128, 28, 28]),
('nb_params', 0)])),
('Conv2d-45',
OrderedDict([('input_shape', [-1, 128, 28, 28]),
('output_shape', [-1, 128, 28, 28]),
('trainable', False),
('nb_params', 147456)])),
('BatchNorm2d-46',
OrderedDict([('input_shape', [-1, 128, 28, 28]),
('output_shape', [-1, 128, 28, 28]),
('trainable', False),
('nb_params', 256)])),
('ReLU-47',
OrderedDict([('input_shape', [-1, 128, 28, 28]),
('output_shape', [-1, 128, 28, 28]),
('nb_params', 0)])),
('BasicBlock-48',
OrderedDict([('input_shape', [-1, 128, 28, 28]),
('output_shape', [-1, 128, 28, 28]),
('nb_params', 0)])),
('Conv2d-49',
OrderedDict([('input_shape', [-1, 128, 28, 28]),
('output_shape', [-1, 128, 28, 28]),
('trainable', False),
('nb_params', 147456)])),
('BatchNorm2d-50',
OrderedDict([('input_shape', [-1, 128, 28, 28]),
('output_shape', [-1, 128, 28, 28]),
('trainable', False),
('nb_params', 256)])),
('ReLU-51',
OrderedDict([('input_shape', [-1, 128, 28, 28]),
('output_shape', [-1, 128, 28, 28]),
('nb_params', 0)])),
('Conv2d-52',
OrderedDict([('input_shape', [-1, 128, 28, 28]),
('output_shape', [-1, 128, 28, 28]),
('trainable', False),
('nb_params', 147456)])),
('BatchNorm2d-53',
OrderedDict([('input_shape', [-1, 128, 28, 28]),
('output_shape', [-1, 128, 28, 28]),
('trainable', False),
('nb_params', 256)])),
('ReLU-54',
OrderedDict([('input_shape', [-1, 128, 28, 28]),
('output_shape', [-1, 128, 28, 28]),
('nb_params', 0)])),
('BasicBlock-55',
OrderedDict([('input_shape', [-1, 128, 28, 28]),
('output_shape', [-1, 128, 28, 28]),
('nb_params', 0)])),
('Conv2d-56',
OrderedDict([('input_shape', [-1, 128, 28, 28]),
('output_shape', [-1, 256, 14, 14]),
('trainable', False),
('nb_params', 294912)])),
('BatchNorm2d-57',
OrderedDict([('input_shape', [-1, 256, 14, 14]),
('output_shape', [-1, 256, 14, 14]),
('trainable', False),
('nb_params', 512)])),
('ReLU-58',
OrderedDict([('input_shape', [-1, 256, 14, 14]),
('output_shape', [-1, 256, 14, 14]),
('nb_params', 0)])),
('Conv2d-59',
OrderedDict([('input_shape', [-1, 256, 14, 14]),
('output_shape', [-1, 256, 14, 14]),
('trainable', False),
('nb_params', 589824)])),
('BatchNorm2d-60',
OrderedDict([('input_shape', [-1, 256, 14, 14]),
('output_shape', [-1, 256, 14, 14]),
('trainable', False),
('nb_params', 512)])),
('Conv2d-61',
OrderedDict([('input_shape', [-1, 128, 28, 28]),
('output_shape', [-1, 256, 14, 14]),
('trainable', False),
('nb_params', 32768)])),
('BatchNorm2d-62',
OrderedDict([('input_shape', [-1, 256, 14, 14]),
('output_shape', [-1, 256, 14, 14]),
('trainable', False),
('nb_params', 512)])),
('ReLU-63',
OrderedDict([('input_shape', [-1, 256, 14, 14]),
('output_shape', [-1, 256, 14, 14]),
('nb_params', 0)])),
('BasicBlock-64',
OrderedDict([('input_shape', [-1, 128, 28, 28]),
('output_shape', [-1, 256, 14, 14]),
('nb_params', 0)])),
('Conv2d-65',
OrderedDict([('input_shape', [-1, 256, 14, 14]),
('output_shape', [-1, 256, 14, 14]),
('trainable', False),
('nb_params', 589824)])),
('BatchNorm2d-66',
OrderedDict([('input_shape', [-1, 256, 14, 14]),
('output_shape', [-1, 256, 14, 14]),
('trainable', False),
('nb_params', 512)])),
('ReLU-67',
OrderedDict([('input_shape', [-1, 256, 14, 14]),
('output_shape', [-1, 256, 14, 14]),
('nb_params', 0)])),
('Conv2d-68',
OrderedDict([('input_shape', [-1, 256, 14, 14]),
('output_shape', [-1, 256, 14, 14]),
('trainable', False),
('nb_params', 589824)])),
('BatchNorm2d-69',
OrderedDict([('input_shape', [-1, 256, 14, 14]),
('output_shape', [-1, 256, 14, 14]),
('trainable', False),
('nb_params', 512)])),
('ReLU-70',
OrderedDict([('input_shape', [-1, 256, 14, 14]),
('output_shape', [-1, 256, 14, 14]),
('nb_params', 0)])),
('BasicBlock-71',
OrderedDict([('input_shape', [-1, 256, 14, 14]),
('output_shape', [-1, 256, 14, 14]),
('nb_params', 0)])),
('Conv2d-72',
OrderedDict([('input_shape', [-1, 256, 14, 14]),
('output_shape', [-1, 256, 14, 14]),
('trainable', False),
('nb_params', 589824)])),
('BatchNorm2d-73',
OrderedDict([('input_shape', [-1, 256, 14, 14]),
('output_shape', [-1, 256, 14, 14]),
('trainable', False),
('nb_params', 512)])),
('ReLU-74',
OrderedDict([('input_shape', [-1, 256, 14, 14]),
('output_shape', [-1, 256, 14, 14]),
('nb_params', 0)])),
('Conv2d-75',
OrderedDict([('input_shape', [-1, 256, 14, 14]),
('output_shape', [-1, 256, 14, 14]),
('trainable', False),
('nb_params', 589824)])),
('BatchNorm2d-76',
OrderedDict([('input_shape', [-1, 256, 14, 14]),
('output_shape', [-1, 256, 14, 14]),
('trainable', False),
('nb_params', 512)])),
('ReLU-77',
OrderedDict([('input_shape', [-1, 256, 14, 14]),
('output_shape', [-1, 256, 14, 14]),
('nb_params', 0)])),
('BasicBlock-78',
OrderedDict([('input_shape', [-1, 256, 14, 14]),
('output_shape', [-1, 256, 14, 14]),
('nb_params', 0)])),
('Conv2d-79',
OrderedDict([('input_shape', [-1, 256, 14, 14]),
('output_shape', [-1, 256, 14, 14]),
('trainable', False),
('nb_params', 589824)])),
('BatchNorm2d-80',
OrderedDict([('input_shape', [-1, 256, 14, 14]),
('output_shape', [-1, 256, 14, 14]),
('trainable', False),
('nb_params', 512)])),
('ReLU-81',
OrderedDict([('input_shape', [-1, 256, 14, 14]),
('output_shape', [-1, 256, 14, 14]),
('nb_params', 0)])),
('Conv2d-82',
OrderedDict([('input_shape', [-1, 256, 14, 14]),
('output_shape', [-1, 256, 14, 14]),
('trainable', False),
('nb_params', 589824)])),
('BatchNorm2d-83',
OrderedDict([('input_shape', [-1, 256, 14, 14]),
('output_shape', [-1, 256, 14, 14]),
('trainable', False),
('nb_params', 512)])),
('ReLU-84',
OrderedDict([('input_shape', [-1, 256, 14, 14]),
('output_shape', [-1, 256, 14, 14]),
('nb_params', 0)])),
('BasicBlock-85',
OrderedDict([('input_shape', [-1, 256, 14, 14]),
('output_shape', [-1, 256, 14, 14]),
('nb_params', 0)])),
('Conv2d-86',
OrderedDict([('input_shape', [-1, 256, 14, 14]),
('output_shape', [-1, 256, 14, 14]),
('trainable', False),
('nb_params', 589824)])),
('BatchNorm2d-87',
OrderedDict([('input_shape', [-1, 256, 14, 14]),
('output_shape', [-1, 256, 14, 14]),
('trainable', False),
('nb_params', 512)])),
('ReLU-88',
OrderedDict([('input_shape', [-1, 256, 14, 14]),
('output_shape', [-1, 256, 14, 14]),
('nb_params', 0)])),
('Conv2d-89',
OrderedDict([('input_shape', [-1, 256, 14, 14]),
('output_shape', [-1, 256, 14, 14]),
('trainable', False),
('nb_params', 589824)])),
('BatchNorm2d-90',
OrderedDict([('input_shape', [-1, 256, 14, 14]),
('output_shape', [-1, 256, 14, 14]),
('trainable', False),
('nb_params', 512)])),
('ReLU-91',
OrderedDict([('input_shape', [-1, 256, 14, 14]),
('output_shape', [-1, 256, 14, 14]),
('nb_params', 0)])),
('BasicBlock-92',
OrderedDict([('input_shape', [-1, 256, 14, 14]),
('output_shape', [-1, 256, 14, 14]),
('nb_params', 0)])),
('Conv2d-93',
OrderedDict([('input_shape', [-1, 256, 14, 14]),
('output_shape', [-1, 256, 14, 14]),
('trainable', False),
('nb_params', 589824)])),
('BatchNorm2d-94',
OrderedDict([('input_shape', [-1, 256, 14, 14]),
('output_shape', [-1, 256, 14, 14]),
('trainable', False),
('nb_params', 512)])),
('ReLU-95',
OrderedDict([('input_shape', [-1, 256, 14, 14]),
('output_shape', [-1, 256, 14, 14]),
('nb_params', 0)])),
('Conv2d-96',
OrderedDict([('input_shape', [-1, 256, 14, 14]),
('output_shape', [-1, 256, 14, 14]),
('trainable', False),
('nb_params', 589824)])),
('BatchNorm2d-97',
OrderedDict([('input_shape', [-1, 256, 14, 14]),
('output_shape', [-1, 256, 14, 14]),
('trainable', False),
('nb_params', 512)])),
('ReLU-98',
OrderedDict([('input_shape', [-1, 256, 14, 14]),
('output_shape', [-1, 256, 14, 14]),
('nb_params', 0)])),
('BasicBlock-99',
OrderedDict([('input_shape', [-1, 256, 14, 14]),
('output_shape', [-1, 256, 14, 14]),
('nb_params', 0)])),
('Conv2d-100',
OrderedDict([('input_shape', [-1, 256, 14, 14]),
('output_shape', [-1, 512, 7, 7]),
('trainable', False),
('nb_params', 1179648)])),
('BatchNorm2d-101',
OrderedDict([('input_shape', [-1, 512, 7, 7]),
('output_shape', [-1, 512, 7, 7]),
('trainable', False),
('nb_params', 1024)])),
('ReLU-102',
OrderedDict([('input_shape', [-1, 512, 7, 7]),
('output_shape', [-1, 512, 7, 7]),
('nb_params', 0)])),
('Conv2d-103',
OrderedDict([('input_shape', [-1, 512, 7, 7]),
('output_shape', [-1, 512, 7, 7]),
('trainable', False),
('nb_params', 2359296)])),
('BatchNorm2d-104',
OrderedDict([('input_shape', [-1, 512, 7, 7]),
('output_shape', [-1, 512, 7, 7]),
('trainable', False),
('nb_params', 1024)])),
('Conv2d-105',
OrderedDict([('input_shape', [-1, 256, 14, 14]),
('output_shape', [-1, 512, 7, 7]),
('trainable', False),
('nb_params', 131072)])),
('BatchNorm2d-106',
OrderedDict([('input_shape', [-1, 512, 7, 7]),
('output_shape', [-1, 512, 7, 7]),
('trainable', False),
('nb_params', 1024)])),
('ReLU-107',
OrderedDict([('input_shape', [-1, 512, 7, 7]),
('output_shape', [-1, 512, 7, 7]),
('nb_params', 0)])),
('BasicBlock-108',
OrderedDict([('input_shape', [-1, 256, 14, 14]),
('output_shape', [-1, 512, 7, 7]),
('nb_params', 0)])),
('Conv2d-109',
OrderedDict([('input_shape', [-1, 512, 7, 7]),
('output_shape', [-1, 512, 7, 7]),
('trainable', False),
('nb_params', 2359296)])),
('BatchNorm2d-110',
OrderedDict([('input_shape', [-1, 512, 7, 7]),
('output_shape', [-1, 512, 7, 7]),
('trainable', False),
('nb_params', 1024)])),
('ReLU-111',
OrderedDict([('input_shape', [-1, 512, 7, 7]),
('output_shape', [-1, 512, 7, 7]),
('nb_params', 0)])),
('Conv2d-112',
OrderedDict([('input_shape', [-1, 512, 7, 7]),
('output_shape', [-1, 512, 7, 7]),
('trainable', False),
('nb_params', 2359296)])),
('BatchNorm2d-113',
OrderedDict([('input_shape', [-1, 512, 7, 7]),
('output_shape', [-1, 512, 7, 7]),
('trainable', False),
('nb_params', 1024)])),
('ReLU-114',
OrderedDict([('input_shape', [-1, 512, 7, 7]),
('output_shape', [-1, 512, 7, 7]),
('nb_params', 0)])),
('BasicBlock-115',
OrderedDict([('input_shape', [-1, 512, 7, 7]),
('output_shape', [-1, 512, 7, 7]),
('nb_params', 0)])),
('Conv2d-116',
OrderedDict([('input_shape', [-1, 512, 7, 7]),
('output_shape', [-1, 512, 7, 7]),
('trainable', False),
('nb_params', 2359296)])),
('BatchNorm2d-117',
OrderedDict([('input_shape', [-1, 512, 7, 7]),
('output_shape', [-1, 512, 7, 7]),
('trainable', False),
('nb_params', 1024)])),
('ReLU-118',
OrderedDict([('input_shape', [-1, 512, 7, 7]),
('output_shape', [-1, 512, 7, 7]),
('nb_params', 0)])),
('Conv2d-119',
OrderedDict([('input_shape', [-1, 512, 7, 7]),
('output_shape', [-1, 512, 7, 7]),
('trainable', False),
('nb_params', 2359296)])),
('BatchNorm2d-120',
OrderedDict([('input_shape', [-1, 512, 7, 7]),
('output_shape', [-1, 512, 7, 7]),
('trainable', False),
('nb_params', 1024)])),
('ReLU-121',
OrderedDict([('input_shape', [-1, 512, 7, 7]),
('output_shape', [-1, 512, 7, 7]),
('nb_params', 0)])),
('BasicBlock-122',
OrderedDict([('input_shape', [-1, 512, 7, 7]),
('output_shape', [-1, 512, 7, 7]),
('nb_params', 0)])),
('Flatten-123',
OrderedDict([('input_shape', [-1, 512, 7, 7]),
('output_shape', [-1, 25088]),
('nb_params', 0)])),
('Linear-124',
OrderedDict([('input_shape', [-1, 25088]),
('output_shape', [-1, 4]),
('trainable', True),
('nb_params', 100356)]))])
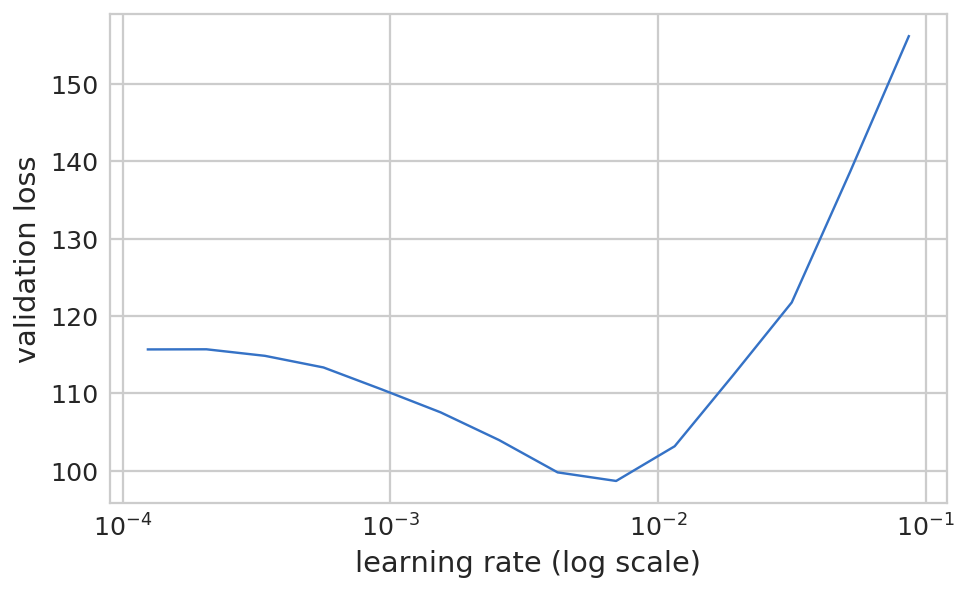
训练 1 2 3 learn.lr_find(1e-5 ,100 ) learn.sched.plot(5 )
HBox(children=(IntProgress(value=0, description='Epoch', max=1), HTML(value='')))
78%|███████▊ | 25/32 [00:07<00:02, 2.74it/s, loss=361]
1 learn.fit(lr, 2 ,cycle_len=1 ,cycle_mult=2 )
HBox(children=(IntProgress(value=0, description='Epoch', max=3), HTML(value='')))
epoch trn_loss val_loss
0 47.500094 35.377468
1 36.438239 30.041442
2 31.159879 28.646647
[array([28.64665])]
1 2 lrs = np.array([lr/100 ,lr/10 ,lr])
1 2 lrf=learn.lr_find(lrs/1000 ) learn.sched.plot(1 )
HBox(children=(IntProgress(value=0, description='Epoch', max=1), HTML(value='')))
epoch trn_loss val_loss
0 74.022108 27465245354098.688
1 learn.fit(lrs, 2 , cycle_len=1 , cycle_mult=2 )
HBox(children=(IntProgress(value=0, description='Epoch', max=3), HTML(value='')))
epoch trn_loss val_loss
0 25.365956 24.037737
1 22.525828 22.351341
2 19.34687 21.012311
[array([21.01231])]
1 learn.fit(lrs, 1 , cycle_len=2 )
HBox(children=(IntProgress(value=0, description='Epoch', max=2), HTML(value='')))
epoch trn_loss val_loss
0 17.857246 21.15573
1 15.792291 20.153743
[array([20.15374])]
1 2 learn.save('reg4' ) learn.load('reg4' )
1 2 3 4 x,y = next (iter (md.val_dl)) learn.model.eval () preds = to_np(learn.model(VV(x)))
1 2 3 4 5 6 7 8 fig, axes = plt.subplots(3 , 4 , figsize=(12 , 8 )) for i,ax in enumerate (axes.flat): ima=md.val_ds.denorm(to_np(x))[i] b = bb_hw(preds[i]) ax = show_img(ima, ax=ax) draw_rect(ax, b) plt.tight_layout()
WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
单目标检测 对于训练一个神经网络来说,最重要的就是三点
数据
网络结构
损失函数
1 2 3 4 5 6 f_model = resnet34 sz = 224 bs = 64 val_idxs = get_cv_idxs(len (trn_fns))
数据 1 2 3 4 5 6 tfms = tfms_from_model(f_model, sz, crop_type=CropType.NO, tfm_y=TfmType.COORD,aug_tfms=augs) md = ImageClassifierData.from_csv(PATH, JPEGS, BB_CSV,tfms=tfms, bs=bs, continuous=True , val_idxs=val_idxs) md2 = ImageClassifierData.from_csv(PATH, JPEGS, CSV, tfms=tfms_from_model(f_model=f_model, sz=sz))
dataset类可以根据__len__和__getitem__来自定义。
向已有dataset添加第二个label,由此构建一个同时包含BBox和标签的数据集。
1 2 3 4 5 6 7 8 9 10 11 class ConcatLblDataset (Dataset ): def __init__ (self, ds, y2 ): self.ds = ds self.y2 = y2 def __len__ (self ): return len (self.ds) def __getitem__ (self, i ): x, y = self.ds[i] return (x, (y, self.y2[i]))
1 2 3 trn_ds2 = ConcatLblDataset(md.trn_ds, md2.trn_y) val_ds2 = ConcatLblDataset(md.val_ds,md2.val_y)
(array([ 0., 1., 223., 178.], dtype=float32), 14)
1 2 3 md.trn_dl.dataset = trn_ds2 md.val_dl.dataset = val_ds2
1 2 3 4 5 6 x,y = next (iter (md.val_dl)) idx = 3 ima = md.val_ds.ds.denorm(to_np(x))[idx] b = bb_hw(to_np(y[0 ][idx])); b
array([ 1., 60., 223., 127.])
1 2 3 ax = show_img(ima) draw_rect(ax, b) draw_text(ax, b[:2 ], md2.classes[y[1 ][idx]])
网络结构 现在需要的输出是1. 各个类别的激活层(用于判断概率)和2. 生成每个bbox的坐标。
因此最后一层的activation具有4+C个。C表示类别数目.
这次使用线性层,然后加上dropout层提高可靠性。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 head_reg4 = nn.Sequential( Flatten(), nn.ReLU(), nn.Dropout(0.5 ), nn.Linear(25088 , 256 ), nn.ReLU(), nn.BatchNorm1d(256 ), nn.Dropout(0.5 ), nn.Linear(256 , 4 + len (cats)), ) models = ConvnetBuilder(f_model, 0 , 0 ,0 ,custom_head=head_reg4) learn = ConvLearner(md, models=models) learn.opt_fn = optim.Adam
损失函数 定义损失函数和测量函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 def detn_loss (input , target bb_t, c_t = target bb_i, c_i = input [:, :4 ], input [:,4 :] bb_i = F.sigmoid(bb_i) * 224 return F.l1_loss(bb_i, bb_t) + F.cross_entropy(c_i, c_t)*20 def detn_l1 (input , target bb_t, _ = target bb_i = input [:,:4 ] bb_i = F.sigmoid(bb_i) * 224 return F.l1_loss(V(bb_i),V(bb_t)).data def detn_acc (input , target _,c_t = target c_i = input [:,4 :] return accuracy(c_i, c_t) learn.crit = detn_loss learn.metrics = [detn_acc, detn_l1]
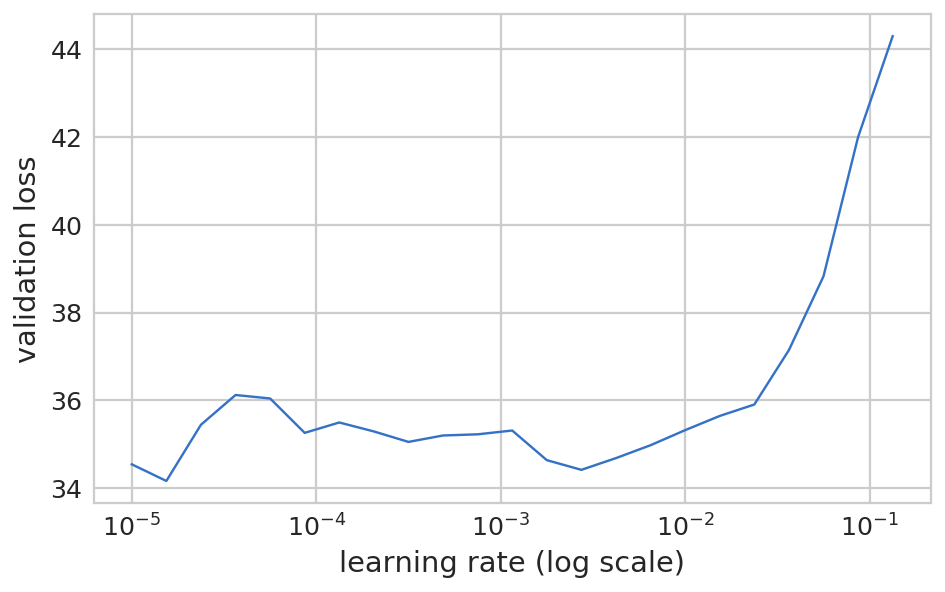
训练 1 2 3 learn.lr_find() learn.sched.plot()
HBox(children=(IntProgress(value=0, description='Epoch', max=1), HTML(value='')))
1 learn.sched.plot(n_skip=5 , n_skip_end=1 )
1 learn.fit(lr, 1 , cycle_len=3 , use_clr=(32 ,5 ))
HBox(children=(IntProgress(value=0, description='Epoch', max=3), HTML(value='')))
epoch trn_loss val_loss detn_acc detn_l1
0 73.021861 49.040769 0.762 33.868816
1 52.371605 39.897777 0.79 26.528015
2 43.085287 38.40951 0.782 25.693656
[array([38.40951]), 0.7820000019073486, 25.693655502319334]
关于use_clr的含义,可以参考:Understanding use_clr
1 lrs = np.array([lr/100 , lr/10 , lr])
1 2 learn.lr_find(lrs/1000 ) learn.sched.plot(0 )
HBox(children=(IntProgress(value=0, description='Epoch', max=1), HTML(value='')))
1 learn.fit(lrs/5 ,1 ,cycle_len=5 ,use_clr=(32 ,10 ))
HBox(children=(IntProgress(value=0, description='Epoch', max=5), HTML(value='')))
epoch trn_loss val_loss detn_acc detn_l1
0 36.869526 38.903723 0.758 24.296154
1 31.326726 36.6155 0.766 21.896477
2 26.642102 33.09029 0.822 21.3755
3 23.477213 33.293454 0.804 21.018092
4 21.219933 32.841205 0.798 20.617818
[array([32.84121]), 0.7979999985694886, 20.617818420410156]
1 2 learn.save('reg1_1' ) learn.load('reg1_1' )
1 2 learn.fit(lrs/10 , 1 , cycle_len=10 ,use_clr=(32 ,10 ))
HBox(children=(IntProgress(value=0, description='Epoch', max=10), HTML(value='')))
epoch trn_loss val_loss detn_acc detn_l1
0 18.538771 33.337069 0.808 20.696491
1 18.376943 33.852231 0.784 20.624054
2 17.561372 33.20553 0.802 20.648081
3 16.458471 33.816986 0.786 20.271821
4 15.660971 33.647833 0.792 20.05454
5 14.905726 32.912299 0.784 19.615759
6 14.223394 32.798715 0.79 19.627963
7 13.683377 33.002606 0.788 19.551473
8 13.335879 32.818987 0.79 19.443868
9 13.039377 32.798003 0.784 19.413067
[array([32.798]), 0.784000002861023, 19.413067443847655]
尽管80%的准确率不咋地,因为ResNet这个网络本身是用来进行分类的,而不是预测BBOX的回归预测的。
同时,可以看到的是,在做准确率(分类问题)和BBox同时预测是,L1损失看起来比只做BBox预测要低。这是为何?
这样来看,判断出图像中的主要的物体是什么是比较困难的步骤,然后再去判断主要物体的BBox和类别相比之下较为轻松。所以当有一个用于预测图中主要物体是什么以及BBox在哪时,它们会共享所有的计算,共享则意味着计算的高效,当进行分类误差与定位误差的反向传播时,共享的信息能够有助于找到图像中最大的物体。
1 2 learn.save("reg1" ) learn.load("reg1" )
预测 1 2 3 y = learn.predict() x,_ = next (iter (md.val_dl))
1 from scipy.special import expit
1 2 3 4 5 6 7 8 9 10 fig, axes = plt.subplots(3 ,4 ,figsize=(12 ,8 )) for i,ax in enumerate (axes.flat): ima = md.val_ds.ds.denorm(to_np(x))[i] bb = expit(y[i][:4 ])*224 b = bb_hw(bb) c = np.argmax(y[i][4 :]) ax = show_img(ima, ax=ax) draw_rect(ax, b) draw_text(ax, b[:2 ], md2.classes[c]) plt.tight_layout()
WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
这次主要展示的MultiBox目标检测中的第一步:single object detection(单目标的检测,图像中单个主要的目标)。
可以看到存在的问题是,当出现群体目标时,BBox会框住群体中心区域,这显然是不对的。
End