目标检测训练技巧集锦(论文笔记)
Bag of Freebies for Training Object Detection Neural Networks
紧接着上次那篇用于CNN图像分类的技巧集锦论文《Bag of Tricks for Image Classification with Convolutional Neural Networks》,这是AWS出的第二篇关于深度学习神经网络训练的炼丹技巧的论文。
与上次关注的图像分类领域不同,这篇论文聚焦于目标检测领域。不同于较为通用的图像分类(简单来说就是Backbone特征提取的事情),目标检测更加复杂(检测目标不同,优化的策略和目标也不同)。
作者做的事情就是通过调研最近的发表的文献,并进行实验,总结出一些可用于目标检测领域的训练技巧(这些技巧通常是无关检测目标的技巧,因此具有较高的通用性)。
论文题目中的Bag of Freebies指的就是这些方法都是不涉及网络框架的训练技巧,比如图像扩增,学习率设置等,因此在提升检测精度的情况下,不需要牺牲推理时间。
下面就是论文中提出的一些方法。
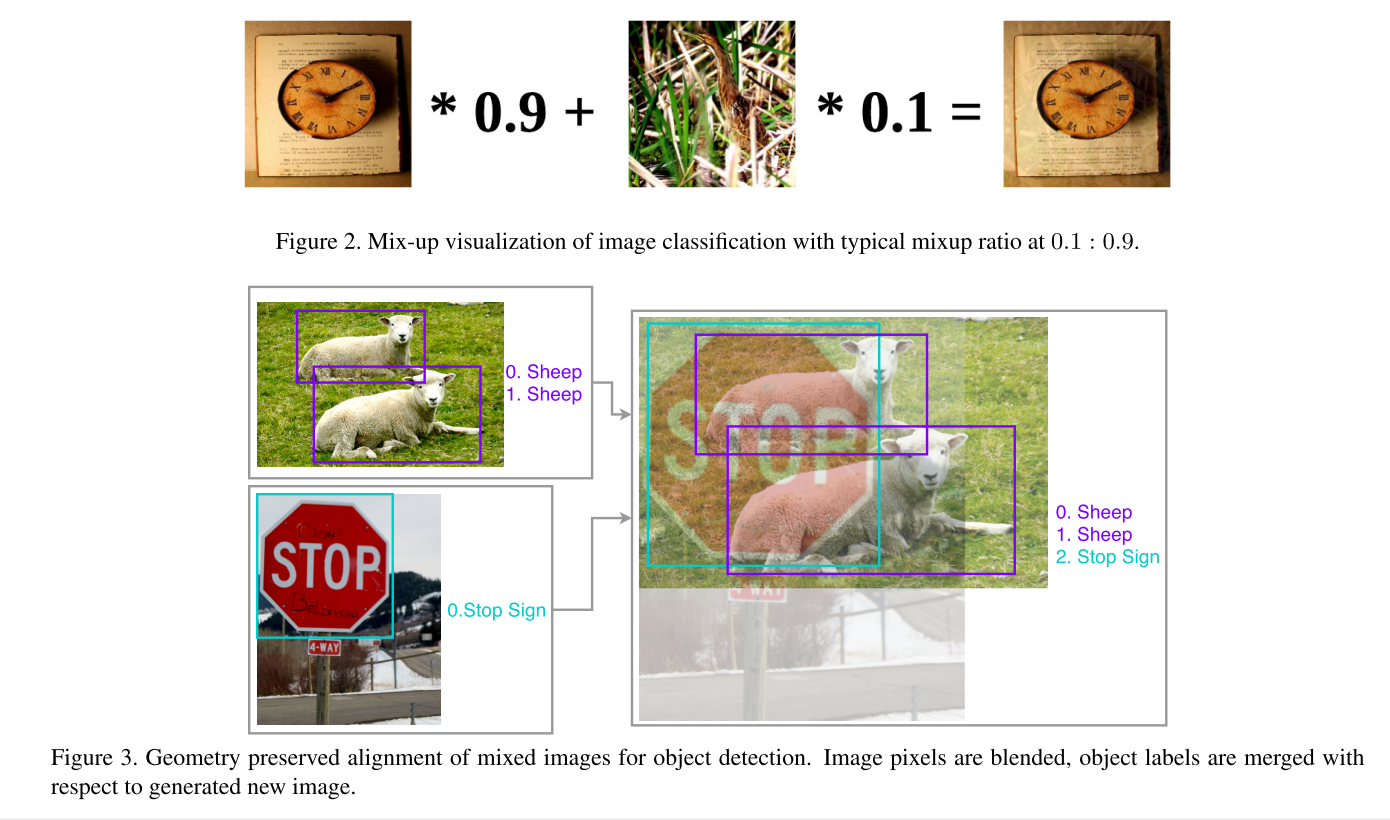
Visually Coherent Image Mixup(视觉相关图像混合)
- 一种数据增广手段。
- 创新点来自论文**《mixup: Beyond empirical risk minimization》(ICLR 2018)**。
- 原理示意可以看图,上图为分类数据集中的混合方法,下图为目标检测数据集中的混合方法。
![mixup]()
- 从原理可知,该方法引入了两个重要参数,就是混合时两张图像的权重(α和β),不同参数对结果的影响也不同,关于参数的效果可以看论文。
- 意义何在?达到遮挡的效果,实现数据增广。通过使用这种复杂的空间变换,就可以引入遮挡,而遮挡确确实实是存在于自然的图像表征中的。
Classification Head Label Smoothing
一种优化策略。
创新点来自论文《Rethinking the inception architecture for computer vision》 [1]
原理解释如下:
检测网络在分类任务上,通常是先得到分类预测网络上最后一个线性层的输出$z$,$z_i$表示每一类没有经过归一化的的单位输出。
通过softMax函数可以计算出每一类的置信度($C$表示分类数目),从而得到预测的分布:
$$
p_i = \frac {e^{z_i}} {\sum_{i=1}^C {e^{z_i}}}
$$通常情况下,接下来计算的分类损失用的是cross entropy(交叉熵)。根据上式的预测分布$p$和ground truth真值分布$q$ 计算cross entropy:
$$
L = \sum_{i=1}^C {q_i log p_i}
$$上面就是主流的计算方法,那么优化的点来了:
真值分布q实际上是独热分布(one-hot distribution),即正确分类概率为1,其余为0。而由于$z_i>>z_j, \forall j \neq i $,预测分布p永远也达不到独热分布的水平,从而会多计算出了不必要的Loss(即分类正确也产生loss),这样就成了过拟合的一个因素。Label Smoothing的意义就在于通过在真值分布上引入噪声,从而“平滑”真值分布,也就减少了预测分布与真值分布的交叉熵,防止过拟合。一式以蔽之:
$$
q_{i}^{i} = (1-\epsilon) q_i + \frac{\epsilon}{C}
$$$\epsilon$是一个小常量,C是总的分类个数。
[1]: https://zhuanlan.zhihu.com/p/56700862 “亚马逊提出:目标检测训练秘籍(代码已开源)”
数据预处理(Data Preprocess)
- 两类数据增广手段。
- 随机几何变换:
- 随机裁剪(带约束)
- 随机扩展
- 随机水平翻转
- 随机缩放(带随机插值)
- 随机颜色抖动:包括亮度、色调、饱和度和对比度。
- 随机几何变换:
- 需要注意的是作者根据两类目标检测框架去讨论
- one-stage 目标检测,如YOLOv3,则几何变换和颜色抖动都可以添加。
- two-stage 目标检测,如Faster-RCNN,由于RPN过程中存在采样过程,在特征图上有着重复的操作,取代了随机裁剪,因此对于two-stage的检测器,在数据集上不需要几何上的数据增广。
训练过程优化(Training Scheduler Revamping)
关于学习率的设置,通常是步进调整策略(step schedule)。即设定的一个base learning rate,每隔K个迭代,按照比例缩小learning rate。step schedule的缺点就在于:
- 变更学习率时有学习率的突变,需要optimizer在接下来几个迭代中去重新稳定这个突变引起的动量;
- 还有一个问题就是初始的学习率较高,有梯度爆炸风险。
基于以上两者,分别有Cosine schdule(余弦策略)和Warm up(预热策略)。这两种其实都是常见的优化方式,就不具体介绍了,用下图来表示,红线就是warm up + cosine schedule的结合: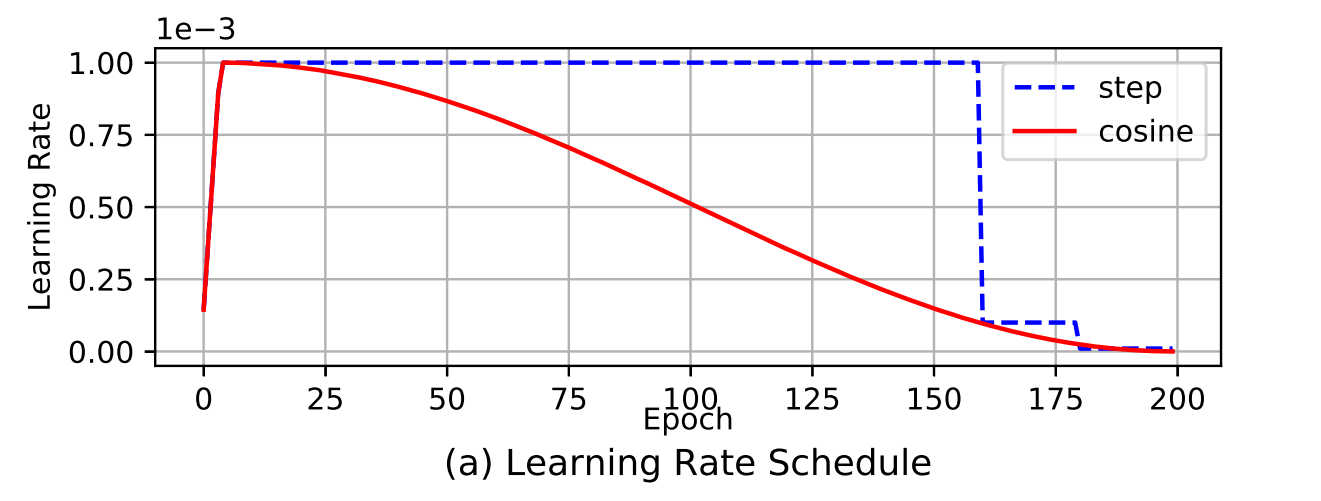
Synchronized Batch Normalization(跨GPU batch归一化)
这里讲的就是Batch Normalization在跨卡训练时的作用。
用于single stage 检测网络的随机形状训练
- 一种数据增广手段(其实并没有,只是改变了输入图像分辨率)
- 通常single stage的训练为了限制内存,会使用固定大小的图像,即对数据集中的图像缩放成固定的大小进行训练。
- 为了减小过拟合,增加网络泛化性能。作者的做法是将同一个Batch的图像调整为$Nx3xHxW$,其中$H和W$是从一个数字序列中随机选择的。比如在YOLOv3中,$H=W \in \lbrace 320,352,384,416,448,480,512,544,576,608\rbrace$ ,每个Batch从这组序列中随机选一个进行训练。
实验结果就不贴了,对自己的训练帮助能有多大还是得上手测试一下。
参考文章列表: