Tip-Review-Algorithm 第八期
Tip
删除DerivedData的正确方式
没错,正确的方式就是在Finder中将DerivedData文件夹移动到废纸篓中。
Deleting DerivedData the right way 这篇文章提到了直接在Terminal中通过rm -fR进行删除是一种错误的方式。
大致意思就是说,macOS上有个 Launch Services 能够当当前运行的App打开其他App或者文件等,就跟在Finder中打开文件、App一样。当你安装一个应用程序的时候,Finder会自动向Launch Services注册该应用程序;但是,当你用Xcode编译一个应用程序时,这个注册不是显示发生的,而是在构建过程中Xcode自己注册的。(讲到这里,突然感觉这个删除方式跟Xcode构建iOS App没啥关系,因为App build结束也不会在Macos展示出来,暴汗…)。
当你把应用程序放进废纸篓时,Finder能够在Launch Services中自动注销应用程序,但是 rm 命令绕过了废纸篓,也就绕过了Launch Services,导致DerivedData文件夹中的任何注册应用程序都将留在Launch Services中。
文章还讲了一些在调用rm命令时自动触发删除Launch Services的方法,就不展开讲了。
快速找到DerivedData的方式如下,你也可以自己定义文件夹位置。
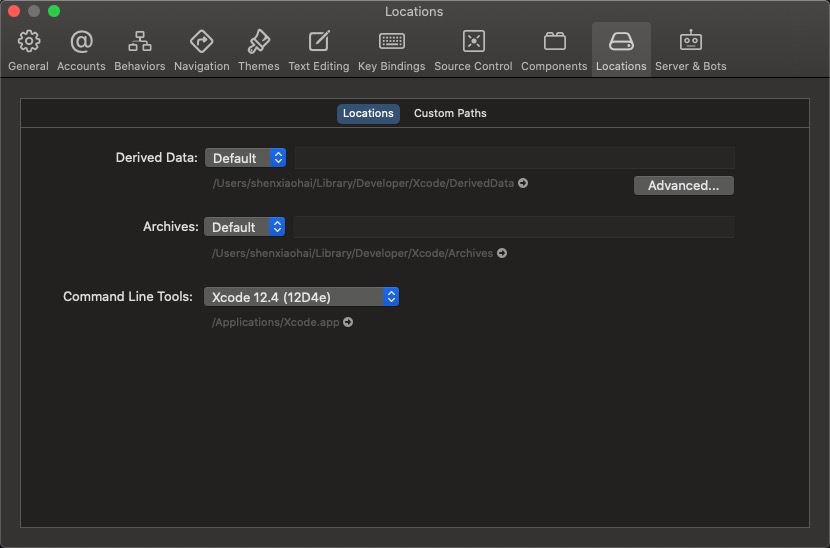
Review
七个数据库范例
有个Youtuber推荐给大家,Fireship。他有个100s系列,就是用100s的时间来讲一个开发领域的基本概念,不能说深入,但能拓展视野。这次做笔记的视频是 7 Database Paradigms(7个数据库范例)。
Key-Value Database 「键值数据库」
- 简介:数据库本身的结构几乎类似于JavaScript对象或Python字典,其中我们拥有一组键,并且每个键都是唯一的并指向某个值。
- 热门数据库:Redis、memcached。
- 用途:
- 大多数情况下,它们被用作缓存来减少数据延迟。Twitter、 GitHub 和 Snapchat 等应用程序都使用 Redis 来实时传输数据。
- 除了缓存之外,还有其他一些用例,比如消息队列、发布订阅和游戏排行榜。但通常情况下,键值数据库被用作其他一些持久数据之上的缓存。
Wide-Column Database 「列存储数据库」
- 简介:一个宽列数据库就像是一个键值数据库,然后向其添加第二个维度。在外层,你有一个键空间可以容纳一个或多个列族,每个列族可以容纳一组有序的行,这样就可以将相关的数据组织在一起,但是不像关系数据库文档,它没有模式,所以它只能处理非结构化数据文档。这对于开发人员来说是件好事,因为你得到了一个称为 CQL 的查询语言,它与 SQL 非常相似,尽管它更有限,你不能连接,但是它更容易扩展。与 SQL 数据库不同,它是分散的,可以水平扩展。
- 热门数据库:Cassandra、HBase。
- 用途:
- 它可以用来扩展大量的时间序列数据,比如来自物联网设备、气象传感器的记录,或者你的Nerflix上的观看记录。
- 它用在频繁写入,但不经常更新和读取的场景下。
Document Oriented Database 「面向文档的数据库」
- 简介:在这种类型中,每个文档都是键值对的容器。它们是非结构化的,不需要模式。可以被索引,可以被组织成一个逻辑层次结构,允许我们对关系数据高度地建模和检索。
- 热门数据库:MongoDB、 Firestore、 DynamoDB、 Couch DB。
- 用途:
- 它们通常适用于物联网内容管理、移动游戏和许多其他场景。
- 如果您不确定数据是如何结构化的,那么文档数据库可能是最好的起点。
The Relational Database 「关系型数据库」
- 简介:算了。
- 热门数据库: MySQL、 Postgres、 SQL Server 。
- 用途:
- SQL 数据库特性:原子性、一致性、隔离性、持久性,这意味着只要数据库中有事务,即使出现网络或硬件故障,也能保证数据的有效性。这对于银行和金融机构来说是必不可少的。
Graph Database 「图数据库」
- 简介:支持对图数据模型的增、删、改、查(CRUD)。
- 热门数据库:Neo4J、Dgraph。
- 用途:
- 它们通常用于欺诈检测,或者用于公司内部知识图谱的构建,
- 又或者用于推荐系统,比如airbnb。
A Full Text Search Engine 「全文搜索引擎」
简介:工作方式与面向文档的数据库非常相似。从索引开始,然后向其中添加数据对象。不同之处在于,引擎将分析文档中的所有文本,并创建可搜索术语的索引。本质上,它的工作原理就像你在教科书后面找到的索引,当用户进行搜索时,它只需要扫描索引。与数据库中的每个文档不同,即使在大型数据集上,引擎也可以运行各种不同的算法对结果进行排序,过滤掉不相关的点击,处理输入错误,等等。
热门数据库:Elasticsearch、Algolia。
用途:各类搜索引擎。
Multi Model Database 「多模型数据库」
- 下一代、灵活、综合、统一,balabala。
Algorithm
leetcode322. 零钱兑换
描述:
给定不同面额的硬币 coins 和一个总金额 amount。编写一个函数来计算可以凑成总金额所需的最少的硬币个数。如果没有任何一种硬币组合能组成总金额,返回 -1。
你可以认为每种硬币的数量是无限的。
思路:
动态规划基本套路。
1 | /* |